Vo väčšine prípadov sú údaje sústredené okolo nejakého centrálneho bodu. Na opísanie akéhokoľvek súboru údajov teda stačí uviesť priemernú hodnotu. Uvažujme postupne tri číselné charakteristiky, ktoré sa používajú na odhad priemernej hodnoty rozdelenia: aritmetický priemer, medián a modus.
Priemerná
Aritmetický priemer (často nazývaný jednoducho priemer) je najbežnejším odhadom priemeru rozdelenia. Je to výsledok vydelenia súčtu všetkých pozorovaných číselných hodnôt ich počtom. Pre vzorku pozostávajúcu z čísel X 1, X 2, ..., Xn, vzorový priemer (označený ) sa rovná = (X1 + X2 + … + Xn) / n, alebo
kde je priemer vzorky, n- veľkosť vzorky, Xi– i-tý prvok vzorky.
Stiahnite si poznámku vo formáte alebo formáte, príklady vo formáte
Zvážte výpočet aritmetického priemeru päťročných priemerných ročných výnosov 15 veľmi rizikových podielových fondov (obrázok 1).

Ryža. 1. Priemerné ročné výnosy 15 veľmi rizikových podielových fondov
Priemer vzorky sa vypočíta takto:

Ide o dobrý výnos, najmä v porovnaní s výnosom 3 – 4 %, ktorý vkladatelia bánk alebo družstevných bánk dostali za rovnaké časové obdobie. Ak zoradíme výnosy, ľahko zistíme, že osem fondov má výnosy nad priemerom a sedem pod priemerom. Aritmetický priemer funguje ako bod rovnováhy, takže fondy s nízkymi výnosmi vyvažujú prostriedky s vysokými výnosmi. Všetky prvky vzorky sa podieľajú na výpočte priemeru. Žiadny z ostatných odhadov priemeru rozdelenia nemá túto vlastnosť.
Kedy by ste mali vypočítať aritmetický priemer? Keďže aritmetický priemer závisí od všetkých prvkov vo vzorke, prítomnosť extrémnych hodnôt významne ovplyvňuje výsledok. V takýchto situáciách môže aritmetický priemer skresliť význam číselných údajov. Preto pri popise súboru údajov obsahujúcich extrémne hodnoty je potrebné uviesť medián alebo aritmetický priemer a medián. Napríklad, ak zo vzorky odstránime výnosy fondu RS Emerging Growth, priemerná vzorka výnosov 14 fondov sa zníži o takmer 1 % na 5,19 %.
Medián
Medián predstavuje strednú hodnotu usporiadaného poľa čísel. Ak pole neobsahuje opakujúce sa čísla, polovica jeho prvkov bude menšia a polovica väčšia ako medián. Ak vzorka obsahuje extrémne hodnoty, je lepšie použiť na odhad priemeru skôr medián ako aritmetický priemer. Na výpočet mediánu vzorky je potrebné ju najskôr objednať.
Tento vzorec je nejednoznačný. Jeho výsledok závisí od toho, či je číslo párne alebo nepárne n:
- Ak vzorka obsahuje nepárny počet prvkov, medián je (n+1)/2- prvok.
- Ak vzorka obsahuje párny počet prvkov, medián leží medzi dvoma strednými prvkami vzorky a rovná sa aritmetickému priemeru vypočítanému pre tieto dva prvky.
Na výpočet mediánu vzorky obsahujúcej výnosy 15 veľmi rizikových podielových fondov musíte najskôr zoradiť nespracované údaje (obrázok 2). Potom bude medián oproti číslu stredného prvku vzorky; v našom príklade č.8. Excel má špeciálnu funkciu =MEDIAN(), ktorá pracuje aj s neusporiadanými poľami.

Ryža. 2. Medián 15 fondov
Medián je teda 6,5. To znamená, že výnos jednej polovice veľmi rizikových fondov nepresahuje 6,5 a výnos druhej polovice ju prevyšuje. Všimnite si, že medián 6,5 nie je oveľa väčší ako priemer 6,08.
Ak zo vzorky odstránime výnos fondu RS Emerging Growth, potom sa medián zvyšných 14 fondov zníži na 6,2 %, teda nie tak výrazne ako aritmetický priemer (obrázok 3).

Ryža. 3. Medián 14 fondov
Móda
Termín prvýkrát vytvoril Pearson v roku 1894. Móda je číslo, ktoré sa vo vzorke vyskytuje najčastejšie (najmódnejšie). Móda dobre popisuje napríklad typickú reakciu vodičov na signál semaforov, aby sa zastavili. Klasickým príkladom využitia módy je výber veľkosti topánok či farby tapety. Ak má distribúcia niekoľko režimov, potom sa hovorí, že je multimodálna alebo multimodálna (má dva alebo viac „vrcholov“). Multimodalita distribúcie poskytuje dôležité informácie o povahe skúmanej premennej. Napríklad v sociologických prieskumoch, ak premenná predstavuje preferenciu alebo postoj k niečomu, potom multimodalita môže znamenať, že existuje niekoľko výrazne odlišných názorov. Multimodalita tiež slúži ako indikátor toho, že vzorka nie je homogénna a pozorovania môžu byť generované dvoma alebo viacerými „prekrývajúcimi sa“ distribúciami. Na rozdiel od aritmetického priemeru odľahlé hodnoty neovplyvňujú režim. Pre priebežne distribuované náhodné premenné, ako je priemerný ročný výnos podielových fondov, režim niekedy vôbec neexistuje (alebo nemá zmysel). Keďže tieto indikátory môžu nadobúdať veľmi odlišné hodnoty, opakujúce sa hodnoty sú extrémne zriedkavé.
Kvartily
Kvartily sú metriky, ktoré sa najčastejšie používajú na vyhodnotenie distribúcie údajov pri popise vlastností veľkých numerických vzoriek. Zatiaľ čo medián rozdeľuje usporiadané pole na polovicu (50 % prvkov poľa je menších ako medián a 50 % je väčších), kvartily rozdeľujú usporiadaný súbor údajov na štyri časti. Hodnoty Q 1, mediánu a Q 3 sú 25., 50. a 75. percentil. Prvý kvartil Q 1 je číslo, ktoré rozdeľuje vzorku na dve časti: 25 % prvkov je menších ako prvý kvartil a 75 % je väčších ako prvý kvartil.
Tretí kvartil Q 3 je číslo, ktoré tiež rozdeľuje vzorku na dve časti: 75 % prvkov je menších a 25 % je väčších ako tretí kvartil.
Na výpočet kvartilov vo verziách Excelu pred rokom 2007 použite funkciu =QUARTILE(pole,časť). Od Excelu 2010 sa používajú dve funkcie:
- =QUARTILE.ON(pole,časť)
- =QUARTILE.EXC(pole,časť)
Tieto dve funkcie poskytujú mierne odlišné hodnoty (obrázok 4). Napríklad pri výpočte kvartilov vzorky obsahujúcej priemerné ročné výnosy 15 veľmi rizikových podielových fondov, Q 1 = 1,8 alebo –0,7 pre QUARTILE.IN a QUARTILE.EX, v tomto poradí. Mimochodom, predtým používaná funkcia QUARTILE zodpovedá modernej funkcii QUARTILE.ON. Na výpočet kvartilov v Exceli pomocou vyššie uvedených vzorcov nie je potrebné usporiadať dátové pole.

Ryža. 4. Výpočet kvartilov v Exceli
Ešte raz zdôraznime. Excel dokáže vypočítať kvartily pre jednu premennú diskrétne série, ktorý obsahuje hodnoty náhodnej premennej. Výpočet kvartilov pre frekvenčné rozdelenie je uvedený nižšie v časti.
Geometrický priemer
Na rozdiel od aritmetického priemeru vám geometrický priemer umožňuje odhadnúť mieru zmeny premennej v čase. Geometrický priemer je koreň n stupeň z práce n veličiny (v Exceli sa používa funkcia =SRGEOM):
G= (X 1 * X 2 * ... * X n) 1/n
Podobný parameter - geometrická stredná hodnota miery zisku - je určený vzorcom:
G = [(1 + R 1) * (1 + R 2) * … * (1 + R n)] 1/n – 1,
Kde RI– miera zisku za ičasové obdobie.
Predpokladajme napríklad, že počiatočná investícia je 100 000 USD. Do konca prvého roka klesne na 50 000 USD a do konca druhého roka sa vráti na počiatočnú úroveň 100 000 USD. Miera návratnosti tejto investície za dva -ročné obdobie sa rovná 0, pretože počiatočná a konečná výška prostriedkov sa navzájom rovnajú. Aritmetický priemer ročnej miery návratnosti je však = (–0,5 + 1) / 2 = 0,25 alebo 25 %, pretože miera návratnosti v prvom roku R 1 = (50 000 – 100 000) / 100 000 = –0,5 , a v druhom R 2 = (100 000 – 50 000) / 50 000 = 1. Zároveň sa geometrická stredná hodnota miery zisku za dva roky rovná: G = [(1–0,5) * (1+ 1 )] 1/2 – 1 = ½ – 1 = 1 – 1 = 0. Geometrický priemer teda presnejšie odráža zmenu (presnejšie absenciu zmien) v objeme investície za dvojročné obdobie ako aritmetický priemer.
Zaujímavosti. Po prvé, geometrický priemer bude vždy menší ako aritmetický priemer tých istých čísel. S výnimkou prípadu, keď sa všetky načítané čísla navzájom rovnajú. Po druhé, zvážením vlastností pravouhlého trojuholníka môžete pochopiť, prečo sa priemer nazýva geometrický. Výška pravouhlého trojuholníka zníženého k prepone je priemerná úmernosť medzi projekciami nôh na preponu a každá noha je priemerná úmernosť medzi preponami a jej projekciou do prepony (obr. 5). Toto poskytuje geometrický spôsob, ako zostrojiť geometrický priemer dvoch (dĺžok) segmentov: musíte zo súčtu týchto dvoch segmentov zostrojiť kruh ako priemer, potom výšku obnovenú od bodu ich spojenia po priesečník s kružnicou. poskytne požadovanú hodnotu:

Ryža. 5. Geometrický charakter geometrického priemeru (obrázok z Wikipédie)
Druhou dôležitou vlastnosťou číselných údajov je ich variácia, charakterizujúce stupeň rozptylu údajov. Dve rôzne vzorky sa môžu líšiť priemerom aj rozptylom. Ako je však znázornené na obr. 6 a 7, dve vzorky môžu mať rovnaké variácie, ale rôzne prostriedky, alebo rovnaké prostriedky a úplne odlišné variácie. Údaje, ktoré zodpovedajú polygónu B na obr. 7 sa menia oveľa menej ako údaje, na ktorých bol polygón A skonštruovaný.

Ryža. 6. Dve symetrické distribúcie v tvare zvona s rovnakým rozptylom a rôznymi strednými hodnotami

Ryža. 7. Dve symetrické distribúcie v tvare zvona s rovnakými strednými hodnotami a rôznymi rozpätiami
Existuje päť odhadov variácií údajov:
- rozsah,
- medzikvartilový rozsah,
- rozptyl,
- štandardná odchýlka,
- variačný koeficient.
Rozsah
Rozsah je rozdiel medzi najväčším a najmenším prvkom vzorky:
Rozsah = XMax – XMin
Rozsah vzorky obsahujúcej priemerné ročné výnosy 15 veľmi rizikových podielových fondov možno vypočítať pomocou usporiadaného poľa (pozri obrázok 4): Rozsah = 18,5 – (–6,1) = 24,6. To znamená, že rozdiel medzi najvyšším a najnižším priemerným ročným výnosom veľmi rizikových fondov je 24,6 %.
Rozsah meria celkové rozšírenie údajov. Hoci rozsah vzoriek je veľmi jednoduchým odhadom celkového rozptylu údajov, jeho slabinou je, že nezohľadňuje presne to, ako sú údaje rozdelené medzi minimálny a maximálny prvok. Tento efekt je jasne viditeľný na obr. 8, ktorý znázorňuje vzorky s rovnakým rozsahom. Stupnica B ukazuje, že ak vzorka obsahuje aspoň jednu extrémnu hodnotu, rozsah vzorky je veľmi nepresným odhadom rozptylu údajov.

Ryža. 8. Porovnanie troch vzoriek s rovnakým rozsahom; trojuholník symbolizuje oporu stupnice a jeho umiestnenie zodpovedá priemeru vzorky
Interkvartilný rozsah
Medzikvartilový alebo priemerný rozsah je rozdiel medzi tretím a prvým kvartilom vzorky:
Interkvartilové rozpätie = Q 3 – Q 1
Táto hodnota nám umožňuje odhadnúť rozptyl 50% prvkov a nebrať do úvahy vplyv extrémnych prvkov. Interkvartilné rozpätie vzorky obsahujúcej priemerné ročné výnosy 15 veľmi rizikových podielových fondov možno vypočítať pomocou údajov na obr. 4 (napríklad pre funkciu QUARTILE.EXC): Interkvartilový rozsah = 9,8 – (–0,7) = 10,5. Interval ohraničený číslami 9,8 a -0,7 sa často nazýva stredná polovica.
Je potrebné poznamenať, že hodnoty Q1 a Q3, a teda medzikvartilový rozsah, nezávisia od prítomnosti odľahlých hodnôt, pretože ich výpočet nezohľadňuje žiadnu hodnotu, ktorá by bola menšia ako Q1 alebo väčšia. ako Q3. Súhrnné miery, ako je medián, prvý a tretí kvartil a medzikvartilové rozpätie, ktoré nie sú ovplyvnené odľahlými hodnotami, sa nazývajú robustné miery.
Hoci rozsah a medzikvartilový rozsah poskytujú odhady celkového a priemerného rozptylu vzorky, ani jeden z týchto odhadov nezohľadňuje presne to, ako sú údaje rozdelené. Rozptyl a štandardná odchýlka nemajú túto nevýhodu. Tieto ukazovatele vám umožňujú posúdiť mieru, do akej údaje kolíšu okolo priemernej hodnoty. Ukážkový rozptyl je aproximáciou aritmetického priemeru vypočítaného zo štvorcov rozdielov medzi každým prvkom vzorky a priemerom vzorky. Pre vzorku X 1, X 2, ... X n je rozptyl vzorky (označený symbolom S 2 daný nasledujúcim vzorcom:

Vo všeobecnosti je rozptyl vzorky súčet druhých mocnín rozdielov medzi prvkami vzorky a priemerom vzorky, delený hodnotou rovnajúcou sa veľkosti vzorky mínus jedna:

Kde - aritmetický priemer, n- veľkosť vzorky, X i - i výberový prvok X. V Exceli pred verziou 2007 sa na výpočet rozptylu vzorky používala funkcia =VARIN(), od verzie 2010 sa používa funkcia =VARIAN().
Najpraktickejší a všeobecne akceptovaný odhad šírenia údajov je vzorová smerodajná odchýlka. Tento indikátor je označený symbolom S a rovná sa druhej odmocnine rozptylu vzorky:

V Exceli pred verziou 2007 sa na výpočet smerodajnej výberovej odchýlky používala funkcia =STDEV.(), od verzie 2010 sa používa funkcia =STDEV.V(). Na výpočet týchto funkcií môže byť dátové pole neusporiadané.
Ani odchýlka vzorky, ani štandardná odchýlka vzorky nemôžu byť negatívne. Jediná situácia, v ktorej môžu byť ukazovatele S 2 a S nulové, je, ak sú všetky prvky vzorky navzájom rovnaké. V tomto úplne nepravdepodobnom prípade je rozsah a medzikvartilový rozsah tiež nulový.
Číselné údaje sú vo svojej podstate nestále. Každá premenná môže nadobúdať rôzne hodnoty. Napríklad rôzne podielové fondy majú rôznu mieru návratnosti a straty. Vzhľadom na variabilitu číselných údajov je veľmi dôležité študovať nielen odhady priemeru, ktoré majú súhrnný charakter, ale aj odhady rozptylu, ktoré charakterizujú rozptyl údajov.
Rozptyl a štandardná odchýlka vám umožňujú vyhodnotiť rozptyl údajov okolo priemernej hodnoty, inými slovami, určiť, koľko prvkov vzorky je menších ako priemer a koľko väčších. Disperzia má niektoré cenné matematické vlastnosti. Jeho hodnota je však druhá mocnina mernej jednotky – štvorcové percento, štvorcový dolár, štvorcový palec atď. Preto je prirodzenou mierou rozptylu štandardná odchýlka, ktorá je vyjadrená v bežných jednotkách percenta príjmu, dolároch alebo palcoch.
Smerodajná odchýlka vám umožňuje odhadnúť množstvo variácií prvkov vzorky okolo priemernej hodnoty. Takmer vo všetkých situáciách sa väčšina pozorovaných hodnôt nachádza v rozmedzí plus alebo mínus jednej štandardnej odchýlky od priemeru. V dôsledku toho, keď poznáme aritmetický priemer prvkov vzorky a štandardnú odchýlku vzorky, je možné určiť interval, do ktorého patrí väčšina údajov.
Štandardná odchýlka výnosov pre 15 veľmi rizikových podielových fondov je 6,6 (obrázok 9). To znamená, že výnosnosť väčšiny fondov sa od priemernej hodnoty líši najviac o 6,6 % (t. j. kolíše v rozmedzí od – S= 6,2 – 6,6 = –0,4 až +S= 12,8). V skutočnosti je päťročný priemerný ročný výnos 53,3 % (8 z 15) fondov v tomto rozmedzí.

Ryža. 9. Štandardná odchýlka vzorky
Všimnite si, že pri sčítaní štvorcových rozdielov sa položky vzorky, ktoré sú ďalej od priemeru, vážia viac ako položky, ktoré sú bližšie k priemeru. Táto vlastnosť je hlavným dôvodom, prečo sa aritmetický priemer najčastejšie používa na odhad priemeru rozdelenia.
Variačný koeficient
Na rozdiel od predchádzajúcich odhadov rozptylu je variačný koeficient relatívnym odhadom. Vždy sa meria v percentách a nie v jednotkách pôvodných údajov. Variačný koeficient, označený symbolmi CV, meria rozptyl údajov okolo priemeru. Variačný koeficient sa rovná štandardnej odchýlke vydelenej aritmetickým priemerom a vynásobenej 100 %:

Kde S- štandardná odchýlka vzorky, - vzorový priemer.
Variačný koeficient vám umožňuje porovnať dve vzorky, ktorých prvky sú vyjadrené v rôznych jednotkách merania. Napríklad manažér poštovej doručovacej služby má v úmysle obnoviť svoj vozový park. Pri nakladaní balíkov je potrebné zvážiť dve obmedzenia: hmotnosť (v librách) a objem (v kubických stopách) každého balíka. Predpokladajme, že vo vzorke obsahujúcej 200 vriec je priemerná hmotnosť 26,0 libier, štandardná odchýlka hmotnosti je 3,9 libier, stredný objem vrecka je 8,8 kubických stôp a štandardná odchýlka objemu je 2,2 kubických stôp. Ako porovnať rozdiely v hmotnosti a objeme balíkov?
Keďže merné jednotky hmotnosti a objemu sa navzájom líšia, manažér musí porovnávať relatívne rozloženie týchto veličín. Koeficient variácie hmotnosti je CV W = 3,9 / 26,0 * 100 % = 15 % a koeficient variácie objemu je CV V = 2,2 / 8,8 * 100 % = 25 %. Relatívna odchýlka v objeme paketov je teda oveľa väčšia ako relatívna odchýlka v ich hmotnosti.
Distribučný formulár
Treťou dôležitou vlastnosťou vzorky je tvar jej rozloženia. Toto rozdelenie môže byť symetrické alebo asymetrické. Na opísanie tvaru rozdelenia je potrebné vypočítať jeho priemer a medián. Ak sú tieto dve rovnaké, premenná sa považuje za symetricky rozloženú. Ak je stredná hodnota premennej väčšia ako medián, jej rozdelenie má kladnú šikmosť (obr. 10). Ak je medián väčší ako priemer, distribúcia premennej je negatívne skreslená. Pozitívna šikmosť nastáva, keď sa priemer zvýši na nezvyčajne vysoké hodnoty. Negatívna šikmosť nastane, keď priemer klesne na nezvyčajne malé hodnoty. Premenná je symetricky rozdelená, ak nenadobúda žiadne extrémne hodnoty v žiadnom smere, takže veľké a malé hodnoty premennej sa navzájom rušia.

Ryža. 10. Tri typy rozvodov
Údaje uvedené na stupnici A sú negatívne skreslené. Tento obrázok ukazuje dlhý chvost a ľavé zošikmenie spôsobené prítomnosťou nezvyčajne malých hodnôt. Tieto extrémne malé hodnoty posúvajú priemernú hodnotu doľava, čím je menšia ako medián. Údaje zobrazené na stupnici B sú rozdelené symetricky. Ľavá a pravá polovica distribúcie sú zrkadlovým obrazom samých seba. Veľké a malé hodnoty sa navzájom vyrovnávajú a priemer a medián sú rovnaké. Údaje zobrazené na stupnici B sú pozitívne skreslené. Tento obrázok ukazuje dlhý chvost a zošikmenie doprava spôsobené prítomnosťou nezvyčajne vysokých hodnôt. Tieto príliš veľké hodnoty posúvajú priemer doprava, čím je väčší ako medián.
V Exceli je možné získať popisnú štatistiku pomocou doplnku Analytický balík. Prejdite si menu Údaje → Analýza dát, v okne, ktoré sa otvorí, vyberte riadok Deskriptívna štatistika a kliknite Dobre. V okne Deskriptívna štatistika určite uveďte Interval vstupu(obr. 11). Ak chcete zobraziť popisnú štatistiku na rovnakom hárku ako pôvodné údaje, vyberte prepínač Výstupný interval a zadajte bunku, do ktorej má byť umiestnený ľavý horný roh zobrazenej štatistiky (v našom príklade $C$1). Ak chcete vytlačiť údaje do nového hárka alebo nového zošita, stačí vybrať príslušný prepínač. Začiarknite políčko vedľa Súhrnná štatistika. Ak chcete, môžete si tiež vybrať Obtiažnosť,k-tý najmenší ak-tá najväčšia.
Ak na zálohu Údaje v oblasti Analýza nevidíte ikonu Analýza dát, musíte najprv nainštalovať doplnok Analytický balík(pozri napríklad).

Ryža. 11. Popisná štatistika päťročných priemerných ročných výnosov fondov s veľmi vysokou mierou rizika vypočítaná pomocou doplnku Analýza dát Excel programy
Excel vypočítava množstvo štatistík uvedených vyššie: priemer, medián, režim, štandardná odchýlka, rozptyl, rozsah ( interval), minimálna, maximálna a veľkosť vzorky ( skontrolovať). Excel tiež vypočítava niektoré štatistiky, ktoré sú pre nás nové: štandardná chyba, špičatosť a šikmosť. Štandardná chyba rovná štandardnej odchýlke vydelenej druhou odmocninou veľkosti vzorky. Asymetria charakterizuje odchýlku od symetrie rozdelenia a je funkciou, ktorá závisí od kocky rozdielov medzi prvkami vzorky a priemernou hodnotou. Kurtóza je miera relatívnej koncentrácie údajov okolo priemeru v porovnaní s koncami distribúcie a závisí od rozdielov medzi prvkami vzorky a priemerom zvýšeným na štvrtú mocninu.
Výpočet popisnej štatistiky pre populáciu
Priemer, rozptyl a tvar distribúcie diskutovaný vyššie sú charakteristiky určené zo vzorky. Ak však súbor údajov obsahuje číselné merania celej populácie, jeho parametre sa dajú vypočítať. Medzi takéto parametre patrí očakávaná hodnota, rozptyl a štandardná odchýlka populácie.
Očakávaná hodnota rovná sa súčtu všetkých hodnôt v populácii vydelenému veľkosťou populácie:

Kde µ - očakávaná hodnota, Xi- i pozorovanie premennej X, N- objem bežnej populácie. V Exceli sa na výpočet matematického očakávania používa rovnaká funkcia ako pre aritmetický priemer: =AVERAGE().
Populačný rozptyl rovný súčtu štvorcov rozdielov medzi prvkami bežnej populácie a mat. očakávanie delené veľkosťou populácie:

Kde σ 2– rozptyl bežnej populácie. V Exceli pred verziou 2007 sa funkcia =VARP() používa na výpočet rozptylu populácie, počnúc verziou 2010 =VARP().
Smerodajná odchýlka populácie rovná sa druhej odmocnine populačného rozptylu:

V Exceli pred verziou 2007 sa funkcia =STDEV() používa na výpočet štandardnej odchýlky populácie, počnúc verziou 2010 =STDEV.Y(). Všimnite si, že vzorce pre rozptyl populácie a štandardnú odchýlku sa líšia od vzorcov na výpočet rozptylu vzorky a štandardnej odchýlky. Pri výpočte štatistiky vzorky S 2 A S menovateľ zlomku je n – 1 a pri výpočte parametrov σ 2 A σ - objem bežnej populácie N.
Pravidlo palca
Vo väčšine situácií sa veľká časť pozorovaní sústreďuje okolo mediánu a vytvára zhluk. V súboroch údajov s kladným zošikmením je tento zhluk umiestnený naľavo (t. j. pod) od matematického očakávania a v súboroch s negatívnym zošikmením je tento zhluk umiestnený napravo (t. j. nad) od matematického očakávania. Pre symetrické údaje sú priemer a medián rovnaké a pozorovania sa zhlukujú okolo priemeru, čím sa vytvorí zvonovitá distribúcia. Ak distribúcia nie je jasne skreslená a údaje sú sústredené okolo ťažiska, na odhad variability sa dá použiť pravidlo, že ak majú údaje zvonovité rozdelenie, potom približne 68 % pozorovaní je v rámci jedna smerodajná odchýlka očakávanej hodnoty.približne 95 % pozorovaní nie je viac ako dve smerodajné odchýlky od matematického očakávania a 99,7 % pozorovaní nie je viac ako tri smerodajné odchýlky od matematického očakávania.
Preto štandardná odchýlka, ktorá je odhadom priemernej variácie okolo očakávanej hodnoty, pomáha pochopiť, ako sú pozorovania rozdelené, a identifikovať odľahlé hodnoty. Pravidlom je, že pre zvonovité rozdelenia sa iba jedna hodnota z dvadsiatich líši od matematického očakávania o viac ako dve štandardné odchýlky. Preto hodnoty mimo intervalu u ± 2σ, možno považovať za odľahlé hodnoty. Okrem toho len tri z 1000 pozorovaní sa líšia od matematického očakávania o viac ako tri štandardné odchýlky. Teda hodnoty mimo intervalu u ± 3σ sú takmer vždy odľahlé. Pre distribúcie, ktoré sú veľmi šikmé alebo nemajú zvonovitý tvar, možno použiť Bienamay-Chebyshevovo pravidlo.
Pred viac ako sto rokmi matematici Bienamay a Chebyshev nezávisle objavili užitočnú vlastnosť štandardnej odchýlky. Zistili, že pre akýkoľvek súbor údajov, bez ohľadu na tvar distribúcie, percento pozorovaní, ktoré ležia vo vzdialenosti kštandardné odchýlky od matematického očakávania, nie menej (1 – 1/ k 2)*100 %.
Napríklad, ak k= 2, pravidlo Bienname-Chebyshev hovorí, že aspoň (1 – (1/2) 2) x 100 % = 75 % pozorovaní musí ležať v intervale u ± 2σ. Toto pravidlo platí pre každého k, presahujúce jednu. Bienamay-Čebyševovo pravidlo je veľmi všeobecné a platné pre distribúcie akéhokoľvek typu. Špecifikuje minimálny počet pozorovaní, pričom vzdialenosť, od ktorej k matematickému očakávaniu nepresahuje stanovenú hodnotu. Ak je však rozdelenie v tvare zvona, pravidlo presnejšie odhadne koncentráciu údajov okolo očakávanej hodnoty.
Výpočet popisných štatistík pre frekvenčne založené rozdelenie
Ak pôvodné údaje nie sú k dispozícii, jediným zdrojom informácií sa stáva rozdelenie frekvencií. V takýchto situáciách je možné vypočítať približné hodnoty kvantitatívnych ukazovateľov rozdelenia, ako je aritmetický priemer, štandardná odchýlka a kvartily.
Ak sú údaje vzorky reprezentované ako frekvenčné rozdelenie, aproximáciu aritmetického priemeru možno vypočítať za predpokladu, že všetky hodnoty v rámci každej triedy sú sústredené v strede triedy:

Kde - priemer vzorky, n- počet pozorovaní alebo veľkosť vzorky, s- počet tried vo frekvenčnom rozdelení, m j- stredný bod j trieda, fj- frekvencia zodpovedajúca j- trieda.
Na výpočet štandardnej odchýlky od rozdelenia frekvencií sa tiež predpokladá, že všetky hodnoty v rámci každej triedy sú sústredené v strede triedy.

Aby sme pochopili, ako sa kvartily série určujú na základe frekvencií, zvážte výpočet dolného kvartilu na základe údajov za rok 2013 o rozdelení ruskej populácie podľa priemerného peňažného príjmu na obyvateľa (obr. 12).

Ryža. 12. Podiel ruského obyvateľstva s priemerným peňažným príjmom na obyvateľa za mesiac, v rubľoch
Na výpočet prvého kvartilu série variácií intervalu môžete použiť vzorec:

kde Q1 je hodnota prvého kvartilu, xQ1 je spodná hranica intervalu obsahujúceho prvý kvartil (interval je určený akumulovanou frekvenciou, ktorá ako prvá prekročí 25 %); i – intervalová hodnota; Σf – súčet frekvencií celej vzorky; pravdepodobne sa vždy rovná 100 %; SQ1–1 – akumulovaná frekvencia intervalu predchádzajúceho intervalu obsahujúcemu dolný kvartil; fQ1 – frekvencia intervalu obsahujúceho dolný kvartil. Vzorec pre tretí kvartil sa líši v tom, že na všetkých miestach musíte použiť Q3 namiesto Q1 a nahradiť ¾ namiesto ¼.
V našom príklade (obr. 12) je dolný kvartil v rozmedzí 7000,1 – 10 000, ktorého akumulovaná frekvencia je 26,4 %. Dolná hranica tohto intervalu je 7 000 rubľov, hodnota intervalu je 3 000 rubľov, akumulovaná frekvencia intervalu predchádzajúceho intervalu obsahujúceho dolný kvartil je 13,4 %, frekvencia intervalu obsahujúceho dolný kvartil je 13,0 %. Teda: Q1 = 7000 + 3000 * (¼ * 100 – 13,4) / 13 = 9677 rub.
Úskalia spojené s popisnou štatistikou
V tomto príspevku sme sa pozreli na to, ako opísať množinu údajov pomocou rôznych štatistík, ktoré vyhodnocujú jej priemer, rozšírenie a distribúciu. Ďalším krokom je analýza a interpretácia údajov. Doteraz sme skúmali objektívne vlastnosti údajov a teraz prejdeme k ich subjektívnej interpretácii. Výskumník čelí dvom chybám: nesprávne zvolenému predmetu analýzy a nesprávnej interpretácii výsledkov.
Analýza výnosov 15 veľmi rizikových podielových fondov je celkom nezaujatá. Dospel k úplne objektívnym záverom: všetky podielové fondy majú rozdielne výnosy, spread výnosov fondov sa pohybuje od -6,1 do 18,5 a priemerný výnos je 6,08. Objektívnosť analýzy dát je zabezpečená správnou voľbou súhrnných kvantitatívnych ukazovateľov rozloženia. Zvažovalo sa niekoľko metód odhadu priemeru a rozptylu údajov a naznačili sa ich výhody a nevýhody. Ako si vybrať správnu štatistiku, ktorá poskytne objektívnu a nestrannú analýzu? Ak je distribúcia údajov mierne skreslená, mali by ste zvoliť skôr medián ako priemer? Ktorý ukazovateľ presnejšie charakterizuje šírenie údajov: smerodajná odchýlka alebo rozsah? Mali by sme poukázať na to, že distribúcia je pozitívne skreslená?
Na druhej strane je interpretácia údajov subjektívnym procesom. Rôzni ľudia prichádzajú k rôznym záverom pri interpretácii rovnakých výsledkov. Každý má svoj vlastný uhol pohľadu. Niekto považuje celkové priemerné ročné výnosy 15 fondov s veľmi vysokou mierou rizika za dobré a je celkom spokojný s dosiahnutým príjmom. Iní môžu mať pocit, že tieto fondy majú príliš nízke výnosy. Subjektivita by teda mala byť kompenzovaná čestnosťou, neutralitou a jasnosťou záverov.
Etické problémy
Analýza údajov je neoddeliteľne spojená s etickými otázkami. Mali by ste byť kritickí k informáciám šíreným novinami, rádiom, televíziou a internetom. Časom sa naučíte byť skeptickí nielen k výsledkom, ale aj k cieľom, predmetu a objektivite výskumu. Slávny britský politik Benjamin Disraeli to povedal najlepšie: „Existujú tri druhy klamstiev: klamstvá, prekliate klamstvá a štatistiky.
Ako sa uvádza v poznámke, pri výbere výsledkov, ktoré by sa mali prezentovať v správe, vznikajú etické problémy. Mali by sa zverejňovať pozitívne aj negatívne výsledky. Okrem toho pri vypracovaní správy alebo písomnej správy musia byť výsledky prezentované čestne, neutrálne a objektívne. Je potrebné rozlišovať medzi neúspešnými a nečestnými prezentáciami. Na to je potrebné určiť, aké boli úmysly rečníka. Niekedy rečník vynechá dôležité informácie z nevedomosti a niekedy je to zámerne (napríklad ak použije aritmetický priemer na odhadnutie priemeru jasne skreslených údajov, aby získal požadovaný výsledok). Nečestné je aj potláčanie výsledkov, ktoré nezodpovedajú pohľadu výskumníka.
Používajú sa materiály z knihy Levin et al Štatistika pre manažérov. – M.: Williams, 2004. – s. 178–209
Funkcia QUARTILE bola zachovaná kvôli kompatibilite so staršími verziami Excelu.
Najviac v rov. V praxi musíme použiť aritmetický priemer, ktorý možno vypočítať ako jednoduchý a vážený aritmetický priemer.
aritmetický priemer (SA)-n Najbežnejší typ priemeru. Používa sa v prípadoch, keď objem premenlivej charakteristiky pre celú populáciu je súčtom hodnôt charakteristík jej jednotlivých jednotiek. Sociálne javy sú charakterizované aditívnosťou (totalitou) objemov rôznej charakteristiky, čo určuje rozsah aplikácie SA a vysvetľuje jej prevalenciu ako všeobecný ukazovateľ, napríklad: všeobecný mzdový fond je súčtom miezd všetkých zamestnancov.
Ak chcete vypočítať SA, musíte vydeliť súčet všetkých hodnôt funkcií ich počtom. SA sa používa v 2 formách.
Zoberme si najprv jednoduchý aritmetický priemer.
1-CA jednoduché (počiatočná, definujúca forma) sa rovná jednoduchému súčtu jednotlivých hodnôt spriemerovanej charakteristiky, vydelenému celkovým počtom týchto hodnôt (používa sa, keď existujú nezoskupené hodnoty indexu charakteristiky):
Vykonané výpočty možno zovšeobecniť do nasledujúceho vzorca:
 (1)
(1)
Kde  - priemerná hodnota premennej charakteristiky, t.j. jednoduchý aritmetický priemer;
- priemerná hodnota premennej charakteristiky, t.j. jednoduchý aritmetický priemer;
 znamená súčet, t. j. sčítanie jednotlivých charakteristík;
znamená súčet, t. j. sčítanie jednotlivých charakteristík;
X- jednotlivé hodnoty rôznej charakteristiky, ktoré sa nazývajú varianty;
n - počet jednotiek obyvateľstva
Príklad 1, je potrebné zistiť priemerný výkon jedného pracovníka (mechanika), ak je známe, koľko dielov vyrobil každý z 15 pracovníkov, t.j. daný rad ind. hodnoty atribútov, ks: 21; 20; 20; 19; 21; 19; 18; 22; 19; 20; 21; 20; 18; 19; 20.
Jednoduchá SA sa vypočíta pomocou vzorca (1), ks:
Príklad2. Vypočítajme SA na základe podmienených údajov pre 20 obchodov zahrnutých v obchodnej spoločnosti (tabuľka 1). stôl 1
Rozdelenie predajní obchodnej spoločnosti "Vesna" podľa predajnej plochy, m2. M
|
Predajňa č. |
Predajňa č. | ||
Na výpočet priemernej predajnej plochy ( 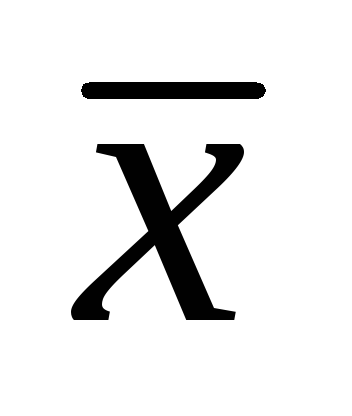 ) je potrebné sčítať plochy všetkých predajní a výsledný výsledok vydeliť počtom predajní:
) je potrebné sčítať plochy všetkých predajní a výsledný výsledok vydeliť počtom predajní:

Priemerná predajná plocha pre túto skupinu maloobchodných podnikov je teda 71 m2.
Preto, aby ste určili jednoduchý SA, musíte vydeliť súčet všetkých hodnôt daného atribútu počtom jednotiek, ktoré majú tento atribút.
2
Kde f 1
,
f 2
,
… ,f n
–
hmotnosť (frekvencia opakovania rovnakých znakov); – súčet súčinov veľkosti znakov a ich frekvencií; – celkový počet jednotiek obyvateľstva.![]() (2)
(2)
Kde X- možnosti;
f- frekvencia (hmotnosť).
Vážený SA je podiel delenia súčtu súčinov opcií a im zodpovedajúcich frekvencií súčtom všetkých frekvencií. Frekvencie ( f) vyskytujúce sa vo vzorci SA sa zvyčajne nazývajú váhy, v dôsledku čoho sa SA vypočítaná s prihliadnutím na váhy nazýva vážená.
Techniku výpočtu váženého SA znázorníme pomocou vyššie uvedeného príkladu 1. Na tento účel zoskupíme počiatočné údaje a umiestnime ich do tabuľky.
Priemer zoskupených údajov sa určí nasledovne: najprv sa možnosti vynásobia frekvenciami, potom sa spočítajú produkty a výsledná suma sa vydelí súčtom frekvencií.
Podľa vzorca (2) sa vážená SA rovná, ks: ![]()

P

Rozdelenie predajní Vesna podľa predajnej plochy, m2. m
Výsledok bol teda rovnaký. Toto však už bude vážený aritmetický priemer.
V predchádzajúcom príklade sme vypočítali aritmetický priemer za predpokladu, že sú známe absolútne frekvencie (počet obchodov). V mnohých prípadoch však chýbajú absolútne frekvencie, ale sú známe relatívne frekvencie, alebo, ako sa bežne nazývajú, frekvencie, ktoré ukazujú podiel resp podiel frekvencií v celom súbore.
Pri výpočte SA váženého použitia frekvencie umožňuje zjednodušiť výpočty, keď je frekvencia vyjadrená veľkými, viaccifernými číslami. Výpočet sa robí rovnakým spôsobom, ale keďže sa ukáže, že priemerná hodnota sa zvýši 100-krát, výsledok by sa mal vydeliť 100.
Potom bude vzorec pre aritmetický vážený priemer vyzerať takto:
Kde d– frekvencia, t.j. podiel každej frekvencie na celkovom súčte všetkých frekvencií.
(3)V našom príklade 2 najskôr určíme podiel predajní podľa skupín na celkovom počte predajní spoločnosti Vesna. Takže pre prvú skupinu špecifická hmotnosť zodpovedá 10%  . Získame nasledujúce údaje Tabuľka 3
. Získame nasledujúce údaje Tabuľka 3
Priemerné hodnoty sa vzťahujú na všeobecné štatistické ukazovatele, ktoré poskytujú súhrnnú (konečnú) charakteristiku masových sociálnych javov, pretože sú postavené na základe veľkého počtu individuálnych hodnôt rôznej charakteristiky. Na objasnenie podstaty priemernej hodnoty je potrebné zvážiť zvláštnosti tvorby hodnôt znakov týchto javov, podľa ktorých sa vypočítava priemerná hodnota.
Je známe, že jednotky každého hromadného javu majú množstvo charakteristík. Bez ohľadu na to, ktorú z týchto charakteristík vezmeme, jej hodnoty sa budú pre jednotlivé jednotky líšiť; menia sa, alebo, ako sa hovorí v štatistikách, sa líšia od jednej jednotky k druhej. Napríklad mzda zamestnanca je určená jeho kvalifikáciou, povahou práce, dĺžkou zamestnania a množstvom ďalších faktorov, a preto sa pohybuje vo veľmi širokých medziach. Súhrnný vplyv všetkých faktorov určuje výšku zárobku každého zamestnanca, avšak môžeme hovoriť o priemernej mesačnej mzde pracovníkov v rôznych odvetviach hospodárstva. Tu pracujeme s typickou charakteristickou hodnotou premenlivej charakteristiky priradenej jednotke veľkej populácie.
Priemerná hodnota to odráža všeobecný,čo je typické pre všetky jednotky skúmanej populácie. Zároveň vyvažuje vplyv všetkých faktorov pôsobiacich na hodnotu charakteristiky jednotlivých jednotiek populácie, akoby ich vzájomne hasili. Úroveň (alebo veľkosť) akéhokoľvek sociálneho javu je daná pôsobením dvoch skupín faktorov. Niektoré z nich sú všeobecné a hlavné, neustále fungujúce, úzko súvisiace s povahou skúmaného javu alebo procesu a tvoria typický pre všetky jednotky skúmanej populácie, čo sa odráža v priemernej hodnote. Iní sú jednotlivec, ich účinok je menej výrazný a je epizodický, náhodný. Pôsobia opačným smerom, spôsobujú rozdiely medzi kvantitatívnymi charakteristikami jednotlivých jednotiek populácie, snažia sa zmeniť konštantnú hodnotu skúmaných charakteristík. Vplyv jednotlivých charakteristík v priemernej hodnote zaniká. V kombinovanom vplyve typických a individuálnych faktorov, ktorý je vo všeobecných charakteristikách vyvážený a vzájomne sa ruší, sa vo všeobecnej podobe prejavuje základný princíp známy z matematickej štatistiky. zákon veľkých čísel.
V súhrne sa jednotlivé hodnoty charakteristík spájajú do spoločnej hmoty a akoby sa rozpúšťajú. Preto priemerná hodnota pôsobí ako „neosobný“, ktorý sa môže odchyľovať od individuálnych hodnôt charakteristík bez toho, aby sa kvantitatívne zhodoval s niektorou z nich. Priemerná hodnota odráža všeobecnú, charakteristickú a typickú pre celú populáciu v dôsledku vzájomného rušenia náhodných, atypických rozdielov v nej medzi charakteristikami jej jednotlivých jednotiek, keďže jej hodnota je určená akoby spoločným výslednicou všetkých príčin.
Aby však priemerná hodnota odrážala najtypickejšiu hodnotu charakteristiky, nemala by sa určovať pre žiadnu populáciu, ale len pre populácie pozostávajúce z kvalitatívne homogénnych jednotiek. Táto požiadavka je hlavnou podmienkou vedecky podloženého používania priemerov a predpokladá úzku súvislosť medzi metódou priemerov a metódou zoskupovania pri analýze sociálno-ekonomických javov. V dôsledku toho je priemerná hodnota všeobecným ukazovateľom charakterizujúcim typickú úroveň premenlivej charakteristiky na jednotku homogénnej populácie v špecifických podmienkach miesta a času.
Pri takto definovaní podstaty priemerných hodnôt je potrebné zdôrazniť, že správny výpočet akejkoľvek priemernej hodnoty predpokladá splnenie nasledujúcich požiadaviek:
- kvalitatívna homogenita populácie, z ktorej sa vypočítava priemerná hodnota. To znamená, že výpočet priemerných hodnôt by mal byť založený na metóde zoskupovania, ktorá zabezpečuje identifikáciu homogénnych, podobných javov;
- s vylúčením vplyvu náhodných, čisto individuálnych príčin a faktorov na výpočet priemernej hodnoty. To sa dosiahne v prípade, keď je výpočet priemeru založený na dostatočne masívnom materiáli, v ktorom sa prejavuje pôsobenie zákona veľkých čísel a ruší sa všetka náhodnosť;
- Pri výpočte priemernej hodnoty je dôležité stanoviť účel jej výpočtu a tzv definujúci ukazovateľ(majetok), na ktorý sa má orientovať.
Definujúci ukazovateľ môže pôsobiť ako súčet hodnôt spriemerovanej charakteristiky, súčet jej prevrátených hodnôt, súčin jej hodnôt atď. Vzťah medzi určujúcim ukazovateľom a priemernou hodnotou je vyjadrený nasledovne: ak sú všetky hodnoty spriemerovanej charakteristiky nahradené priemernou hodnotou, potom ich súčet alebo súčin v tomto prípade nezmení určujúci ukazovateľ. Na základe tohto spojenia medzi definujúcim ukazovateľom a priemernou hodnotou sa zostrojí počiatočný kvantitatívny vzťah pre priamy výpočet priemernej hodnoty. Schopnosť priemerných hodnôt zachovať vlastnosti štatistických populácií sa nazýva definovanie vlastnosti.
Priemerná hodnota vypočítaná pre populáciu ako celok sa nazýva tzv všeobecný priemer; priemerné hodnoty vypočítané pre každú skupinu - skupinové priemery. Všeobecný priemer odráža všeobecné znaky skúmaného javu, skupinový priemer udáva charakteristiku javu, ktorý sa vyvíja v špecifických podmienkach danej skupiny.
Metódy výpočtu môžu byť rôzne, preto v štatistike existuje niekoľko typov priemerov, z ktorých hlavné sú aritmetický priemer, harmonický priemer a geometrický priemer.
V ekonomickej analýze je použitie priemerov hlavným nástrojom hodnotenia výsledkov vedecko-technického pokroku, spoločenských udalostí a hľadania rezerv pre ekonomický rozvoj. Zároveň je potrebné pripomenúť, že nadmerné spoliehanie sa na priemerné ukazovatele môže viesť k skresleným záverom pri vykonávaní ekonomickej a štatistickej analýzy. Je to spôsobené tým, že priemerné hodnoty, ktoré sú všeobecnými ukazovateľmi, potláčajú a ignorujú tie rozdiely v kvantitatívnych charakteristikách jednotlivých jednotiek populácie, ktoré skutočne existujú a môžu byť nezávislé.
Typy priemerov
V štatistike sa používajú rôzne typy priemerov, ktoré sú rozdelené do dvoch veľkých tried:
- mocniny (harmonický priemer, geometrický priemer, aritmetický priemer, kvadratický priemer, kubický priemer);
- štrukturálne prostriedky (modus, medián).
Kalkulovať výkonové priemery je potrebné použiť všetky dostupné charakteristické hodnoty. Móda A medián sú určené len štruktúrou rozdelenia, preto sa nazývajú štrukturálne, polohové priemery. Medián a modus sa často používajú ako priemerná charakteristika v tých populáciách, kde je výpočet stredného výkonu nemožný alebo nepraktický.
Najbežnejším typom priemeru je aritmetický priemer. Pod aritmetický priemer sa chápe ako hodnota charakteristiky, ktorú by mala každá jednotka populácie, ak by celkový súčet všetkých hodnôt charakteristiky bol rozdelený rovnomerne medzi všetky jednotky populácie. Výpočet tejto hodnoty spočíva v súčte všetkých hodnôt meniacej sa charakteristiky a vydelení výsledného množstva celkovým počtom jednotiek v populácii. Napríklad päť robotníkov splnilo objednávku na výrobu dielov, pričom prvý vyrobil 5 dielov, druhý – 7, tretí – 4, štvrtý – 10, piaty – 12. Keďže v zdrojových údajoch bola hodnota každého možnosť sa vyskytla iba raz, na určenie priemerného výkonu jedného pracovníka by sa mal použiť jednoduchý aritmetický priemerný vzorec:
t.j. v našom príklade sa priemerný výkon jedného pracovníka rovná

Spolu s jednoduchým aritmetickým priemerom študujú vážený aritmetický priemer. Vypočítajme si napríklad priemerný vek študentov v skupine 20 ľudí, ktorých vek sa pohybuje od 18 do 22 rokov, kde xi- varianty charakteristiky, ktorá sa spriemeruje, fi- frekvencia, ktorá ukazuje, koľkokrát sa vyskytuje i-tý hodnotu v súhrne (tabuľka 5.1).
Tabuľka 5.1
Priemerný vek študentov
Použitím vzorca váženého aritmetického priemeru dostaneme:

Existuje určité pravidlo pre výber váženého aritmetického priemeru: ak existuje séria údajov o dvoch ukazovateľoch, z ktorých jeden musíte vypočítať
priemerná hodnota a zároveň sú známe číselné hodnoty menovateľa jeho logického vzorca a hodnoty čitateľa sú neznáme, ale možno ich nájsť ako súčin týchto ukazovateľov, potom by mala byť priemerná hodnota sa vypočíta pomocou vzorca aritmetického váženého priemeru.
V niektorých prípadoch je povaha počiatočných štatistických údajov taká, že výpočet aritmetického priemeru stráca zmysel a jediným zovšeobecňujúcim ukazovateľom môže byť iba iný typ priemeru - harmonický priemer. V súčasnosti výpočtové vlastnosti aritmetického priemeru stratili svoj význam pri výpočte všeobecných štatistických ukazovateľov v dôsledku rozsiahleho zavádzania elektronickej výpočtovej techniky. Harmonická stredná hodnota, ktorá môže byť aj jednoduchá a vážená, nadobudla veľký praktický význam. Ak sú známe číselné hodnoty čitateľa logického vzorca a hodnoty menovateľa sú neznáme, ale možno ich nájsť ako čiastočné rozdelenie jedného ukazovateľa druhým, potom sa priemerná hodnota vypočíta pomocou harmonickej vzorec váženého priemeru.
Napríklad, nech je známe, že prvých 210 km auto prešlo rýchlosťou 70 km/h a zvyšných 150 km rýchlosťou 75 km/h. Nie je možné určiť priemernú rýchlosť auta počas celej cesty 360 km pomocou vzorca aritmetického priemeru. Keďže možnosti sú rýchlosti v jednotlivých úsekoch xj= 70 km/h a X2= 75 km/h a závažia (fi) sa považujú za zodpovedajúce úseky trasy, potom súčin možností a závaží nebude mať fyzický ani ekonomický význam. V tomto prípade kvocienty nadobúdajú význam rozdelením úsekov cesty na zodpovedajúce rýchlosti (možnosti xi), t. j. čas strávený prejdením jednotlivých úsekov cesty (fi / xi). Ak sú úseky cesty označené fi, potom je celá cesta vyjadrená ako Σfi a čas strávený na celej ceste je vyjadrený ako Σ fi / xi , Potom priemernú rýchlosť možno nájsť ako podiel celej trasy vydelený celkovým časom stráveným:

V našom príklade dostaneme:

Ak sú pri použití harmonického priemeru váhy všetkých možností (f) rovnaké, potom namiesto váženého môžete použiť jednoduchý (nevážený) harmonický priemer:

kde xi sú jednotlivé možnosti; n- počet variantov spriemerovanej charakteristiky. V rýchlostnom príklade by sa mohol použiť jednoduchý harmonický priemer, ak by boli segmenty dráhy prejdené rôznymi rýchlosťami rovnaké.
Akákoľvek priemerná hodnota sa musí vypočítať tak, aby sa pri nahradení každého variantu spriemerovanej charakteristiky nezmenila hodnota nejakého konečného všeobecného ukazovateľa, ktorý je spojený so spriemerovaným ukazovateľom. Pri nahradení skutočných rýchlostí na jednotlivých úsekoch trasy ich priemernou hodnotou (priemernou rýchlosťou) by sa teda celková vzdialenosť meniť nemala.
Forma (vzorec) priemernej hodnoty je určená povahou (mechanizmom) vzťahu tohto výsledného ukazovateľa k spriemerovanému, preto je konečný ukazovateľ, ktorého hodnota by sa pri nahradení opcií ich priemernou hodnotou nemala meniť. volal definujúci ukazovateľ. Ak chcete odvodiť vzorec pre priemer, musíte vytvoriť a vyriešiť rovnicu pomocou vzťahu medzi spriemerovaným ukazovateľom a určujúcim. Táto rovnica je vytvorená nahradením variantov spriemerovanej charakteristiky (ukazovateľa) ich priemernou hodnotou.
Okrem aritmetického a harmonického priemeru sa v štatistike používajú aj iné typy (formy) priemeru. Všetko sú to špeciálne prípady priemer výkonu. Ak vypočítame všetky typy priemerov výkonu pre rovnaké údaje, potom hodnoty
dopadnú rovnako, tu platí pravidlo hlavná sadzba priemer. So zvyšujúcim sa exponentom priemeru sa zvyšuje aj samotná priemerná hodnota. Najčastejšie používané vzorce na výpočet rôznych typov výkonových priemerov v praktickom výskume sú uvedené v tabuľke. 5.2.
Tabuľka 5.2

Ak existuje, použije sa geometrický priemer n rastové koeficienty, pričom jednotlivé hodnoty charakteristiky sú spravidla hodnoty relatívnej dynamiky, konštruované vo forme reťazových hodnôt, ako pomer k predchádzajúcej úrovni každej úrovne v rade dynamiky. Priemer teda charakterizuje priemernú mieru rastu. Priemerná geometrická jednoduchá vypočítané podľa vzorca

Vzorec vážený geometrický priemer má nasledujúci tvar:

Vyššie uvedené vzorce sú identické, ale jeden sa používa pri súčasných koeficientoch alebo rýchlostiach rastu a druhý - pri absolútnych hodnotách úrovní série.
Hlavné námestie používa sa pri výpočtoch s hodnotami kvadratických funkcií, používa sa na meranie miery fluktuácie jednotlivých hodnôt charakteristiky okolo aritmetického priemeru v distribučnom rade a vypočíta sa podľa vzorca

Vážený stredný štvorec vypočítané pomocou iného vzorca:

Priemerný kubický sa používa pri výpočte s hodnotami kubických funkcií a počíta sa podľa vzorca

priemerná kubická váha:

Všetky vyššie uvedené priemerné hodnoty možno prezentovať ako všeobecný vzorec:

kde je priemerná hodnota; - individuálny význam; n- počet skúmaných jednotiek populácie; k- exponent, ktorý určuje typ priemeru.
Pri použití rovnakých zdrojových údajov tým viac k vo všeobecnom vzorci priemerného výkonu, čím väčšia je priemerná hodnota. Z toho vyplýva, že medzi hodnotami priemerov výkonu existuje prirodzený vzťah:
Vyššie popísané priemerné hodnoty poskytujú všeobecnú predstavu o skúmanej populácii a z tohto hľadiska je ich teoretický, aplikačný a vzdelávací význam nesporný. Stáva sa však, že priemerná hodnota sa nezhoduje so žiadnou zo skutočne existujúcich možností, preto je okrem uvažovaných priemerov v štatistickej analýze vhodné použiť aj hodnoty konkrétnych možností, ktoré zaujímajú veľmi špecifickú pozíciu v usporiadaný (zoradený) rad hodnôt atribútov. Z týchto množstiev sa najčastejšie používajú štrukturálne, alebo popisný, priemerný- režim (Mo) a medián (Me).
Móda- hodnota vlastnosti, ktorá sa najčastejšie vyskytuje v danej populácii. Vo vzťahu k variačnému radu je mód najčastejšie sa vyskytujúcou hodnotou zoradeného radu, teda možnosťou s najvyššou frekvenciou. Móda môže byť použitá pri určovaní obchodov, ktoré sú navštevované častejšie, najbežnejšej ceny akéhokoľvek produktu. Ukazuje veľkosť znaku charakteristického pre významnú časť populácie a je určená vzorcom

kde x0 je spodná hranica intervalu; h- veľkosť intervalu; fm- intervalová frekvencia; fm_ 1 - frekvencia predchádzajúceho intervalu; fm+ 1 - frekvencia nasledujúceho intervalu.
Medián volá sa možnosť umiestnená v strede hodnoteného riadku. Medián rozdeľuje sériu na dve rovnaké časti takým spôsobom, že na oboch jej stranách je rovnaký počet populačných jednotiek. V tomto prípade má jedna polovica jednotiek v populácii hodnotu meniacej sa charakteristiky menšiu ako medián a druhá polovica má hodnotu väčšiu ako je medián. Medián sa používa pri štúdiu prvku, ktorého hodnota je väčšia alebo rovná, alebo súčasne menšia alebo rovná polovici prvkov distribučného radu. Medián poskytuje všeobecnú predstavu o tom, kde sú sústredené hodnoty atribútov, inými slovami, kde je ich stred.
Opisná povaha mediánu sa prejavuje v tom, že charakterizuje kvantitatívnu hranicu hodnôt rôznej charakteristiky, ktorú má polovica jednotiek v populácii. Problém nájdenia mediánu pre sériu diskrétnych variácií je ľahko vyriešený. Ak majú všetky jednotky série poradové čísla, potom sa poradové číslo možnosti medián určí ako (n + 1) / 2 s nepárnym počtom členov n. Ak je počet členov série párne číslo , potom bude medián priemernou hodnotou dvoch možností, ktoré majú sériové čísla n/ 2 a n / 2 + 1.
Pri určovaní mediánu v intervalových variačných sériách najskôr určte interval, v ktorom sa nachádza (mediánový interval). Tento interval je charakteristický tým, že jeho akumulovaný súčet frekvencií sa rovná alebo presahuje polovicu súčtu všetkých frekvencií radu. Medián série intervalových variácií sa vypočíta pomocou vzorca

Kde X0- spodná hranica intervalu; h- veľkosť intervalu; fm- intervalová frekvencia; f- počet členov série;
∫m-1 je súčet akumulovaných členov radu predchádzajúcich danému členu.
Spolu s mediánom, aby sa úplnejšie charakterizovala štruktúra skúmanej populácie, sa používajú aj ďalšie hodnoty možností, ktoré zaujímajú veľmi špecifickú pozíciu v hodnotenej sérii. Tie obsahujú kvartily A decilov. Kvartily rozdeľujú sériu podľa súčtu frekvencií na 4 rovnaké časti a decily - na 10 rovnakých častí. Existujú tri kvartily a deväť decilov.
Medián a modus na rozdiel od aritmetického priemeru neodstraňujú individuálne rozdiely v hodnotách premennej charakteristiky, a preto sú doplnkovými a veľmi dôležitými charakteristikami štatistickej populácie. V praxi sa často používajú namiesto priemeru alebo spolu s ním. Zvlášť vhodné je vypočítať medián a modus v prípadoch, keď skúmaná populácia obsahuje určitý počet jednotiek s veľmi veľkou alebo veľmi malou hodnotou premennej charakteristiky. Tieto hodnoty možností, ktoré nie sú príliš charakteristické pre populáciu, pričom ovplyvňujú hodnotu aritmetického priemeru, neovplyvňujú hodnoty mediánu a režimu, čo z nich robí veľmi cenné ukazovatele pre ekonomické a štatistické analýza.
Variačné ukazovatele
Účelom štatistického výskumu je identifikovať základné vlastnosti a vzorce skúmanej štatistickej populácie. V procese súhrnného spracovania štatistických pozorovacích údajov budujú distribučná séria. Existujú dva typy distribučných radov – atribútové a variačné, v závislosti od toho, či charakteristika, ktorá je základom zoskupenia, je kvalitatívna alebo kvantitatívna.
Variačné sa nazývajú distribučné série konštruované na kvantitatívnom základe. Hodnoty kvantitatívnych charakteristík v jednotlivých jednotkách populácie nie sú konštantné, viac-menej sa navzájom líšia. Tento rozdiel v hodnote charakteristiky sa nazýva variácie. Jednotlivé číselné hodnoty charakteristiky zistenej v skúmanej populácii sa nazývajú varianty hodnôt. Prítomnosť variácií v jednotlivých jednotkách populácie je spôsobená vplyvom veľkého množstva faktorov na formovanie úrovne znaku. Štúdium charakteru a miery variácií charakteristík v jednotlivých jednotkách populácie je najdôležitejšou otázkou každého štatistického výskumu. Variačné indexy sa používajú na opis miery variability vlastností.
Ďalšou dôležitou úlohou štatistického výskumu je určiť úlohu jednotlivých faktorov alebo ich skupín pri variácii určitých charakteristík populácie. Na vyriešenie tohto problému štatistika používa špeciálne metódy na štúdium variácií, ktoré sú založené na použití systému ukazovateľov, pomocou ktorých sa meria variácia. V praxi sa výskumník stretáva s pomerne veľkým počtom variantov hodnôt atribútov, čo nedáva predstavu o rozdelení jednotiek podľa hodnoty atribútu v súhrne. Za týmto účelom usporiadajte všetky varianty charakteristických hodnôt vo vzostupnom alebo zostupnom poradí. Tento proces sa nazýva poradie série. Hodnotená séria okamžite poskytuje všeobecnú predstavu o hodnotách, ktoré funkcia v súhrne nadobúda.
Nedostatočnosť priemernej hodnoty pre vyčerpávajúci popis populácie nás núti doplniť priemerné hodnoty o ukazovatele, ktoré nám umožňujú posúdiť typickosť týchto priemerov meraním variability (variácie) skúmanej charakteristiky. Použitie týchto ukazovateľov variácie umožňuje urobiť štatistickú analýzu úplnejšiu a zmysluplnejšiu, a tým získať hlbšie pochopenie podstaty skúmaných sociálnych javov.
Najjednoduchšie znaky variácie sú minimálne A maximálne - toto je najmenšia a najväčšia hodnota atribútu v súhrne. Počet opakovaní jednotlivých variantov charakteristických hodnôt sa nazýva frekvencia opakovania. Označme frekvenciu opakovania hodnoty atribútu fi, súčet frekvencií rovnajúci sa objemu študovanej populácie bude:
Kde k- počet možností pre hodnoty atribútov. Je vhodné nahradiť frekvencie frekvenciami - wi. Frekvencia- ukazovateľ relatívnej frekvencie - môže byť vyjadrený v zlomkoch jednotky alebo percentách a umožňuje porovnávať série variácií s rôznym počtom pozorovaní. Formálne máme:

Na meranie variácie charakteristiky sa používajú rôzne absolútne a relatívne ukazovatele. Absolútne ukazovatele variácie zahŕňajú priemernú lineárnu odchýlku, rozsah variácie, rozptyl a štandardnú odchýlku.
Rozsah variácií(R) predstavuje rozdiel medzi maximálnymi a minimálnymi hodnotami atribútu v skúmanej populácii: R= Xmax - Xmin. Tento ukazovateľ poskytuje iba najvšeobecnejšiu predstavu o variabilite skúmanej charakteristiky, pretože ukazuje rozdiel iba medzi maximálnymi hodnotami možností. Absolútne nesúvisí s frekvenciami vo variačnom rade, t. j. s povahou rozdelenia, a jeho závislosť mu môže dať nestabilný, náhodný charakter iba od extrémnych hodnôt charakteristiky. Rozsah variácie neposkytuje žiadne informácie o charakteristikách skúmaných populácií a neumožňuje posúdiť mieru typickosti získaných priemerných hodnôt. Rozsah použitia tohto ukazovateľa je obmedzený na pomerne homogénne populácie, presnejšie charakterizuje variáciu charakteristiky, ukazovateľa založeného na zohľadnení variability všetkých hodnôt charakteristiky.
Na charakterizáciu variácie charakteristiky je potrebné zovšeobecniť odchýlky všetkých hodnôt od akejkoľvek hodnoty typickej pre skúmanú populáciu. Takéto ukazovatele
variácie, ako je priemerná lineárna odchýlka, rozptyl a smerodajná odchýlka, sú založené na zohľadnení odchýlok charakteristických hodnôt jednotlivých jednotiek populácie od aritmetického priemeru.
Priemerná lineárna odchýlka predstavuje aritmetický priemer absolútnych hodnôt odchýlok jednotlivých možností od ich aritmetického priemeru:

Absolútna hodnota (modul) odchýlky variantu od aritmetického priemeru; f- frekvencia.
Prvý vzorec sa použije, ak sa každá z možností vyskytuje v súhrne iba raz, a druhý - v sérii s nerovnakými frekvenciami.
Existuje ďalší spôsob spriemerovania odchýlok možností od aritmetického priemeru. Táto veľmi častá metóda v štatistike spočíva v prepočte na druhú mocninu odchýlok opcií od priemernej hodnoty s ich následným spriemerovaním. V tomto prípade získame nový ukazovateľ variácie - disperziu.
Disperzia(σ 2) - priemer druhej mocniny odchýlok možností hodnoty atribútu od ich priemernej hodnoty:

Druhý vzorec sa použije, ak opcie majú svoje vlastné váhy (alebo frekvencie variácií).
V ekonomickej a štatistickej analýze je zvykom hodnotiť variáciu charakteristiky najčastejšie pomocou smerodajnej odchýlky. Smerodajná odchýlka(σ) je druhá odmocnina rozptylu:

Priemerné lineárne a štandardné odchýlky ukazujú, ako veľmi kolíše hodnota charakteristiky v priemere medzi jednotkami skúmanej populácie a sú vyjadrené v rovnakých merných jednotkách ako možnosti.
V štatistickej praxi je často potrebné porovnávať variácie rôznych charakteristík. Napríklad je veľmi zaujímavé porovnávať odchýlky vo veku personálu a jeho kvalifikácie, odpracovanej doby a miezd atď. Na takéto porovnávanie nie sú vhodné ukazovatele absolútnej variability charakteristík - lineárny priemer a smerodajná odchýlka. V skutočnosti je nemožné porovnávať kolísanie dĺžky služby, vyjadrené v rokoch, s kolísaním miezd, vyjadrené v rubľoch a kopejkách.
Pri spoločnom porovnávaní variability rôznych charakteristík je vhodné použiť relatívne miery variácie. Tieto ukazovatele sú vypočítané ako pomer absolútnych ukazovateľov k aritmetickému priemeru (alebo mediánu). Pomocou rozsahu variácie, priemernej lineárnej odchýlky a štandardnej odchýlky ako absolútneho ukazovateľa variácie sa získajú relatívne ukazovatele variability:

Najčastejšie používaný ukazovateľ relatívnej variability, charakterizujúci homogenitu populácie. Populácia sa považuje za homogénnu, ak variačný koeficient nepresahuje 33 % pre distribúcie blízke normálu.
Téma 5. Priemerné hodnoty ako štatistické ukazovatele
Koncept priemernej hodnoty. Rozsah priemerov v štatistickom výskume
Priemerné hodnoty sa používajú vo fáze spracovania a sumarizácie získaných primárnych štatistických údajov. Potreba určiť priemerné hodnoty je spôsobená skutočnosťou, že jednotlivé hodnoty rovnakej charakteristiky pre rôzne jednotky študovaných populácií spravidla nie sú rovnaké.
Priemerná veľkosť nazývaný indikátor, ktorý charakterizuje zovšeobecnenú hodnotu charakteristiky alebo skupiny charakteristík v skúmanej populácii.
Ak sa študuje populácia s kvalitatívne homogénnymi charakteristikami, potom priemerná hodnota tu pôsobí ako typický priemer. Napríklad pre skupiny pracovníkov v určitom odvetví s fixnou úrovňou príjmu sa zisťujú typické priemerné výdavky na základné životné potreby, t.j. typický priemer zovšeobecňuje kvalitatívne homogénne hodnoty atribútu v danej populácii, čo je podiel výdavkov pracovníkov tejto skupiny na základné tovary.
Pri štúdiu populácie s kvalitatívne heterogénnymi charakteristikami môže vystúpiť do popredia atypickosť priemerných ukazovateľov. Sú to napríklad priemerné ukazovatele vyrobeného národného dôchodku na obyvateľa (rôzne vekové skupiny), priemerné ukazovatele výnosov obilia v celom Rusku (regióny rôznych klimatických zón a rôznych obilnín), priemerné ukazovatele pôrodnosti obyvateľstva za všetky regióny krajiny, priemerné teploty za určité obdobie atď. Priemerné hodnoty tu zovšeobecňujú kvalitatívne heterogénne hodnoty charakteristík alebo systémových priestorových agregátov (medzinárodné spoločenstvo, kontinent, štát, región, región atď.) alebo dynamické agregáty predĺžené v čase (storočie, desaťročie, rok, sezóna atď.). ). Takéto priemerné hodnoty sa nazývajú systémové priemery.
Význam priemerných hodnôt teda spočíva v ich zovšeobecňujúcej funkcii. Priemerná hodnota nahrádza veľký počet individuálnych hodnôt atribútu a odhaľuje spoločné vlastnosti, ktoré sú vlastné všetkým jednotkám populácie. To nám zase umožňuje vyhnúť sa náhodným príčinám a identifikovať všeobecné vzorce v dôsledku bežných príčin.
Typy priemerných hodnôt a metódy ich výpočtu
V štádiu štatistického spracovania možno nastaviť rôzne výskumné problémy, na riešenie ktorých je potrebné zvoliť vhodný priemer. V tomto prípade je potrebné riadiť sa nasledujúcim pravidlom: veličiny, ktoré predstavujú čitateľa a menovateľa priemeru, musia spolu logicky súvisieť.
výkonové priemery;
štrukturálne priemery.
Predstavme si nasledujúce konvencie:
množstvá, pre ktoré sa vypočítava priemer;
Priemer, kde stĺpec vyššie naznačuje, že sa uskutočňuje priemerovanie jednotlivých hodnôt;
Frekvencia (opakovateľnosť jednotlivých charakteristických hodnôt).
Zo všeobecného vzorca priemerného výkonu sú odvodené rôzne priemery:
 (5.1)
(5.1)
keď k = 1 - aritmetický priemer; k = -1 - harmonický priemer; k = 0 - geometrický priemer; k = -2 - stredná odmocnina.
Priemerné hodnoty môžu byť jednoduché alebo vážené. Vážené priemery Toto sú hodnoty, ktoré berú do úvahy, že niektoré varianty hodnôt atribútov môžu mať rôzne čísla, a preto je potrebné každú možnosť vynásobiť týmto číslom. Inými slovami, „stupnice“ sú počty agregovaných jednotiek v rôznych skupinách, t.j. Každá možnosť je „vážená“ svojou frekvenciou. Frekvencia f sa nazýva štatistická váha alebo priemerná hmotnosť.
Aritmetický priemer- najbežnejší typ priemeru. Používa sa, keď sa výpočet vykonáva na nezoskupených štatistických údajoch, kde potrebujete získať priemerný termín. Aritmetický priemer je priemerná hodnota charakteristiky, po ktorej získaní zostáva celkový objem charakteristiky v súhrne nezmenený.
Vzorec pre aritmetický priemer (jednoduchý) má tvar
kde n je veľkosť populácie.
Napríklad priemerná mzda zamestnancov podniku sa vypočíta ako aritmetický priemer:

Určujúcimi ukazovateľmi sú tu mzda každého zamestnanca a počet zamestnancov podniku. Pri výpočte priemeru zostala celková výška miezd rovnaká, ale rovnomerne rozdelená medzi všetkých zamestnancov. Napríklad musíte vypočítať priemernú mzdu pracovníkov v malej spoločnosti, ktorá zamestnáva 8 ľudí:
Pri výpočte priemerných hodnôt sa môžu jednotlivé hodnoty spriemerovanej charakteristiky opakovať, takže priemerná hodnota sa vypočíta pomocou zoskupených údajov. V tomto prípade hovoríme o použití vážený aritmetický priemer, ktorý má podobu
 (5.3)
(5.3)
Potrebujeme teda vypočítať priemernú cenu akcií akciovej spoločnosti pri obchodovaní na burze. Je známe, že transakcie sa uskutočnili do 5 dní (5 transakcií), počet akcií predaných za predajný kurz bol rozdelený takto:
1 - 800 ak. - 1010 rubľov.
2 - 650 ak. - 990 rubľov.
3 - 700 ak. - 1015 rubľov.
4 - 550 ak. - 900 rubľov.
5 - 850 ak. - 1150 rubľov.
Počiatočný pomer na určenie priemernej ceny akcií je pomer celkového množstva transakcií (TVA) k počtu predaných akcií (KPA):
OSS = 1010·800+990·650+1015·700+900·550+1150·850= 3 634 500;
KPA = 800 + 650 + 700 + 550 + 850 = 3 550.
V tomto prípade sa priemerná cena akcií rovnala
Je potrebné poznať vlastnosti aritmetického priemeru, čo je veľmi dôležité tak pre jeho použitie, ako aj pre jeho výpočet. Môžeme rozlíšiť tri hlavné vlastnosti, ktoré najviac určovali rozšírené používanie aritmetického priemeru v štatistických a ekonomických výpočtoch.
Vlastnosť jedna (nula): súčet kladných odchýlok jednotlivých hodnôt charakteristiky od jej priemernej hodnoty sa rovná súčtu záporných odchýlok. Toto je veľmi dôležitá vlastnosť, pretože ukazuje, že akékoľvek odchýlky (aj + aj -) spôsobené náhodnými príčinami budú vzájomne anulované.
dôkaz:

Vlastnosť dva (minimum): súčet štvorcových odchýlok jednotlivých hodnôt charakteristiky od aritmetického priemeru je menší ako od akéhokoľvek iného čísla (a), t.j. existuje minimálny počet.
Dôkaz.
Zostavme súčet štvorcových odchýlok od premennej a:
 (5.4)
(5.4)
Na nájdenie extrému tejto funkcie je potrebné prirovnať jej deriváciu vzhľadom na a k nule:

Odtiaľto dostaneme:

 (5.5)
(5.5)
V dôsledku toho sa extrém súčtu kvadrátov odchýlok dosiahne pri . Tento extrém je minimum, pretože funkcia nemôže mať maximum.
Vlastnosť tri: aritmetický priemer konštantnej hodnoty sa rovná tejto konštante: pre a = konšt.
Okrem týchto troch najdôležitejších vlastností aritmetického priemeru existujú tzv dizajnové vlastnosti, ktoré používaním elektronickej výpočtovej techniky postupne strácajú svoj význam:
ak sa individuálna hodnota atribútu každej jednotky vynásobí alebo vydelí konštantným číslom, potom sa aritmetický priemer zvýši alebo zníži o rovnakú hodnotu;
aritmetický priemer sa nezmení, ak sa váha (frekvencia) každej hodnoty atribútu vydelí konštantným číslom;
ak sa jednotlivé hodnoty atribútu každej jednotky znížia alebo zvýšia o rovnakú hodnotu, aritmetický priemer sa zníži alebo zvýši o rovnakú hodnotu.
Harmonický priemer. Tento priemer sa nazýva inverzný aritmetický priemer, pretože táto hodnota sa používa, keď k = -1.
Jednoduchý harmonický priemer sa používa, keď sú váhy hodnôt atribútov rovnaké. Jeho vzorec možno odvodiť zo základného vzorca dosadením k = -1:
Potrebujeme napríklad vypočítať priemernú rýchlosť dvoch áut, ktoré prešli tú istú cestu, ale rôznymi rýchlosťami: prvé pri rýchlosti 100 km/h, druhé pri rýchlosti 90 km/h. Pomocou metódy harmonického priemeru vypočítame priemernú rýchlosť:

V štatistickej praxi sa častejšie používa harmonická vážená, ktorej vzorec má tvar
Tento vzorec sa používa v prípadoch, keď váhy (alebo objemy javov) pre každý atribút nie sú rovnaké. V počiatočnom pomere na výpočet priemeru je čitateľ známy, no menovateľ nie je známy.
V matematike a štatistike priemer aritmetický (alebo jednoduchý priemer) množiny čísel je súčet všetkých čísel v tejto množine vydelený ich počtom. Aritmetický priemer je obzvlášť univerzálnym a najbežnejším vyjadrením priemeru.
Budete potrebovať
- Vedomosti z matematiky.
Inštrukcie
1. Nech je daný súbor štyroch čísel. Treba objaviť priemer význam túto súpravu. Aby sme to dosiahli, najprv nájdeme súčet všetkých týchto čísel. Možné čísla sú 1, 3, 8, 7. Ich súčet je S = 1 + 3 + 8 + 7 = 19. Množina čísel musí pozostávať z čísel rovnakého znamienka, inak stráca zmysel pri výpočte priemernej hodnoty.
2. Priemerná význam množina čísel sa rovná súčtu čísel S vydelenému počtom týchto čísel. To znamená, že sa to ukazuje priemer význam rovná sa: 19/4 = 4,75.
3. Pre sadu čísel je tiež možné zistiť nielen priemer aritmetika, ale aj priemer geometrický. Geometrický priemer niekoľkých pravidelných reálnych čísel je číslo, ktoré môže nahradiť ktorékoľvek z týchto čísel tak, že sa ich súčin nemení. Geometrický priemer G sa hľadá pomocou vzorca: N-tá odmocnina súčinu množiny čísel, kde N je číslo v množine. Pozrime sa na rovnakú množinu čísel: 1, 3, 8, 7. Poďme ich nájsť priemer geometrický. Aby sme to urobili, vypočítajme súčin: 1*3*8*7 = 168. Teraz z čísla 168 musíte extrahovať 4. koreň: G = (168)^1/4 = 3,61. Teda priemer geometrická množina čísel je 3,61.
Priemerná Geometrický priemer sa vo všeobecnosti používa menej často ako aritmetický priemer, môže však byť užitočný pri výpočte priemernej hodnoty ukazovateľov, ktoré sa v čase menia (mzda jednotlivého zamestnanca, dynamika ukazovateľov akademického výkonu atď.).

Budete potrebovať
- Inžiniersky kalkulátor
Inštrukcie
1. Aby ste našli geometrický priemer radu čísel, musíte najprv vynásobiť všetky tieto čísla. Povedzme, že máte množinu piatich ukazovateľov: 12, 3, 6, 9 a 4. Vynásobme všetky tieto čísla: 12x3x6x9x4=7776.
2. Teraz z výsledného čísla musíte extrahovať koreň moci rovnajúci sa počtu prvkov série. V našom prípade z čísla 7776 bude potrebné extrahovať piaty koreň pomocou inžinierskej kalkulačky. Číslo získané po tejto operácii - v tomto prípade číslo 6 - bude geometrickým priemerom pre počiatočnú skupinu čísel.
3. Ak nemáte po ruke inžiniersku kalkulačku, môžete vypočítať geometrický priemer série čísel pomocou funkcie SRGEOM v Exceli alebo pomocou jednej z online kalkulačiek špeciálne navrhnutých na výpočet geometrických stredných hodnôt.
Poznámka!
Ak potrebujete nájsť geometrický priemer každého pre 2 čísla, potom nepotrebujete inžiniersku kalkulačku: môžete extrahovať druhú odmocninu (druhú odmocninu) ľubovoľného čísla pomocou najbežnejšej kalkulačky.
Užitočné rady
Na rozdiel od aritmetického priemeru nie je geometrický priemer tak silne ovplyvnený veľkými odchýlkami a výkyvmi medzi jednotlivými hodnotami v súbore skúmaných ukazovateľov.
Priemerná hodnota je jedným z porovnávaní množiny čísel. Predstavuje číslo, ktoré nemôže byť mimo rozsahu definovaného najväčšou a najmenšou hodnotou v danej množine čísel. Priemerná aritmetická hodnota je obzvlášť bežne používaný typ priemeru.

Inštrukcie
1. Spočítajte všetky čísla v množine a vydeľte ich počtom členov, aby ste dostali aritmetický priemer. V závislosti od určitých podmienok výpočtu je niekedy jednoduchšie rozdeliť každé z čísel počtom hodnôt v množine a sčítať súčet.
2. Ak nie je možné vypočítať aritmetický priemer z vašej hlavy, použite povedzme kalkulačku, ktorá je súčasťou operačného systému Windows. Môžete ho otvoriť s podporou v dialógovom okne spustenia programu. Ak to chcete urobiť, stlačte „klávesové skratky“ WIN + R alebo kliknite na tlačidlo „Štart“ a vyberte príkaz „Spustiť“ z hlavnej ponuky. Potom do vstupného poľa zadajte calc a stlačte kláves Enter na klávesnici alebo kliknite na tlačidlo „OK“. To isté možno vykonať prostredníctvom hlavnej ponuky - otvorte ju, prejdite do časti „Všetky programy“ a do segmentov „Typické“ a vyberte riadok „Kalkulačka“.
3. Postupne zadajte všetky čísla sady stlačením klávesu Plus na klávesnici po všetkých (okrem posledného) alebo kliknutím na príslušné tlačidlo v rozhraní kalkulačky. Čísla môžete zadávať aj z klávesnice alebo kliknutím na príslušné tlačidlá rozhrania.
4. Stlačte lomítko alebo kliknite na túto ikonu v rozhraní kalkulačky po zadaní poslednej hodnoty množiny a zadajte počet čísel v poradí. Potom stlačte znamienko rovnosti a kalkulačka vypočíta a zobrazí aritmetický priemer.
5. Na rovnaký účel môžete použiť aj tabuľkový editor Microsoft Excel. V takom prípade spustite editor a do susedných buniek zadajte všetky hodnoty postupnosti čísel. Ak po zadaní celého čísla stlačíte Enter alebo kláves so šípkou nadol alebo doprava, samotný editor presunie zameranie vstupu do susednej bunky.
6. Vyberte všetky zadané hodnoty a v ľavom dolnom rohu okna editora (v stavovom riadku) uvidíte aritmetický priemer pre vybrané bunky.
7. Ak chcete vidieť iba priemer, kliknite na bunku vedľa posledného zadaného čísla. Rozbaľte rozbaľovací zoznam s obrázkom gréckeho písmena sigma (Σ) v skupine príkazov Úpravy na karte Hlavné. Vyberte riadok " Priemerná“ a editor vloží do vybranej bunky potrebný vzorec na výpočet aritmetického priemeru. Stlačte kláves Enter a hodnota sa vypočíta.
Aritmetický priemer je jednou z mier centrálnej náchylnosti, ktorá sa široko používa v matematike a štatistických výpočtoch. Je veľmi ľahké nájsť aritmetický priemer pre niekoľko hodnôt, ale každý problém má svoje vlastné nuansy, ktoré musíte poznať, aby ste mohli správne výpočty vykonať.

Čo je aritmetický priemer
Aritmetický priemer definuje priemernú hodnotu pre každé počiatočné pole čísel. Inými slovami, z určitej množiny čísel sa vyberie hodnota, ktorá je univerzálna pre všetky prvky, ktorej matematické porovnanie so všetkými prvkami je približne rovnaké. Aritmetický priemer sa používa prednostne pri príprave finančných a štatistických výkazov alebo pri výpočte kvantitatívnych výsledkov podobných zručností.
Ako nájsť aritmetický priemer
Nájdenie aritmetického priemeru pre pole čísel by malo začať určením algebraického súčtu týchto hodnôt. Napríklad, ak pole obsahuje čísla 23, 43, 10, 74 a 34, ich algebraický súčet sa bude rovnať 184. Pri zápise sa aritmetický priemer označuje písmenom? (mu) alebo x (x s čiarou). Ďalej by sa mal algebraický súčet vydeliť počtom čísel v poli. V uvažovanom príklade bolo päť čísel, preto sa aritmetický priemer bude rovnať 184/5 a bude 36,8.
Funkcie práce so zápornými číslami
Ak pole obsahuje záporné čísla, potom sa aritmetický priemer nájde pomocou podobného algoritmu. Rozdiel existuje len pri výpočte v programovacom prostredí, alebo ak problém obsahuje ďalšie údaje. V týchto prípadoch nájdenie aritmetického priemeru čísel s rôznymi znamienkami pozostáva z troch krokov: 1. Hľadanie univerzálneho aritmetického priemeru štandardnou metódou;2. Nájdenie aritmetického priemeru záporných čísel.3. Výpočet aritmetického priemeru kladných čísel Výsledky každej akcie sú oddelené čiarkami.
Prirodzené a desatinné zlomky
Ak je pole čísel reprezentované desatinnými zlomkami, riešenie sa vykoná metódou výpočtu aritmetického priemeru celých čísel, ale zníženie súčtu sa vykoná podľa požiadaviek úlohy na presnosť výsledku. pri práci s prirodzenými zlomkami by sa mali zredukovať na spoločného menovateľa, ktorý sa vynásobí počtom čísel v poli. Čitateľ výsledku bude súčtom daných čitateľov počiatočných zlomkových prvkov.
Geometrický priemer čísel závisí nielen od absolútnej hodnoty samotných čísel, ale aj od ich počtu. Nie je možné zamieňať geometrický priemer a aritmetický priemer čísel, pretože sa zisťujú pomocou rôznych metodológií. V tomto prípade je geometrický priemer vždy menší alebo rovnaký ako aritmetický priemer.

Budete potrebovať
- Inžiniersky kalkulátor.
Inštrukcie
1. Uvažujme, že vo všeobecnom prípade geometrický priemer čísel nájdeme vynásobením týchto čísel a získaním odmocniny mocniny, ktorá zodpovedá počtu čísel. Napríklad, ak potrebujete nájsť geometrický priemer piatich čísel, potom budete musieť extrahovať piaty koreň z produktu.
2. Ak chcete nájsť geometrický priemer 2 čísel, použite základné pravidlo. Nájdite ich súčin, potom vezmite druhú odmocninu čísla dva, ktorá zodpovedá stupňu odmocniny. Povedzme, že ak chcete nájsť geometrický priemer čísel 16 a 4, nájdite ich súčin 16 4 = 64. Z výsledného čísla odoberte druhú odmocninu?64=8. Toto bude požadovaná hodnota. Upozorňujeme, že aritmetický priemer týchto 2 čísel je väčší a rovná sa 10. Ak koreň nie je extrahovaný celý, zaokrúhlite súčet na požadované poradie.
3. Ak chcete nájsť geometrický priemer viac ako 2 čísel, použite aj základné pravidlo. Ak to chcete urobiť, nájdite súčin všetkých čísel, pre ktoré potrebujete nájsť geometrický priemer. Z výsledného produktu extrahujte odmocninu rovnajúcej sa počtu čísel. Napríklad, ak chcete nájsť geometrický priemer čísel 2, 4 a 64, nájdite ich súčin. 2 4 64=512. Pretože je potrebné nájsť výsledok geometrického priemeru 3 čísel, extrahujte zo súčinu tretí koreň. Je ťažké to urobiť verbálne, takže použite inžiniersku kalkulačku. Na tento účel má tlačidlo „x^y“. Vytočte číslo 512, stlačte tlačidlo „x^y“, potom vytočte číslo 3 a stlačením tlačidla „1/x“ nájdite hodnotu 1/3, stlačte tlačidlo „=“. Získame výsledok zvýšenia 512 na 1/3, čo zodpovedá tretiemu odmocneniu. Získajte 512^1/3=8. Toto je geometrický priemer čísel 2,4 a 64.
4. S podporou inžinierskej kalkulačky môžete nájsť geometrický priemer pomocou inej metódy. Nájdite tlačidlo denníka na klávesnici. Potom zoberte logaritmus pre všetky čísla, nájdite ich súčet a vydeľte ho počtom čísel. Zoberte antilogaritmus z výsledného čísla. Toto bude geometrický priemer čísel. Povedzme, že ak chcete nájsť geometrický priemer rovnakých čísel 2, 4 a 64, vykonajte na kalkulačke súbor operácií. Vytočte číslo 2, potom stlačte tlačidlo log, stlačte tlačidlo „+“, vytočte číslo 4 a znova stlačte log a „+“, vytočte 64, stlačte log a „=“. Výsledkom bude číslo, ktoré sa rovná súčtu desatinných logaritmov čísel 2, 4 a 64. Výsledné číslo vydeľte tromi, pretože ide o počet čísel, podľa ktorých sa hľadá geometrický priemer. Zo súčtu zoberte antilogaritmus prepnutím registračného tlačidla a použite rovnaký logovací kľúč. Výsledkom bude číslo 8, to je požadovaný geometrický priemer.
Poznámka!
Priemerná hodnota nemôže byť väčšia ako najväčšie číslo v súbore a menšia ako najmenšie.
Užitočné rady
V matematickej štatistike sa priemerná hodnota veličiny nazýva matematické očakávanie.