In most cases, the data is concentrated around some central point. Thus, to describe any data set, it is enough to indicate the average value. Consider successively three numerical characteristics that are used to estimate the mean value of the distribution: arithmetic mean, median and mode.
Average
The arithmetic mean (often referred to simply as the mean) is the most common estimate of the mean of a distribution. It is the result of dividing the sum of all observed numerical values by their number. For a sample of numbers X 1, X 2, ..., Xn, the sample mean (denoted by the symbol ) equals \u003d (X 1 + X 2 + ... + Xn) / n, or
where is the sample mean, n- sample size, Xi– i-th element of the sample.
Download note in or format, examples in format
Consider calculating the arithmetic average of the five-year average annual returns of 15 very high-risk mutual funds (Figure 1).

Rice. 1. Average annual return on 15 very high-risk mutual funds
The sample mean is calculated as follows:

This is a good return, especially compared to the 3-4% return that bank or credit union depositors received over the same time period. If you sort the return values, it is easy to see that eight funds have a return above, and seven - below the average. The arithmetic mean acts as a balance point, so that low-income funds balance out high-income funds. All elements of the sample are involved in the calculation of the average. None of the other estimators of the distribution mean have this property.
When to calculate the arithmetic mean. Since the arithmetic mean depends on all elements of the sample, the presence of extreme values significantly affects the result. In such situations, the arithmetic mean can distort the meaning of the numerical data. Therefore, when describing a data set containing extreme values, it is necessary to indicate the median or the arithmetic mean and the median. For example, if the return of the RS Emerging Growth fund is removed from the sample, the sample average of the return of the 14 funds decreases by almost 1% to 5.19%.
Median
The median is the middle value of an ordered array of numbers. If the array does not contain repeating numbers, then half of its elements will be less than and half more than the median. If the sample contains extreme values, it is better to use the median rather than the arithmetic mean to estimate the mean. To calculate the median of a sample, it must first be sorted.
This formula is ambiguous. Its result depends on whether the number is even or odd. n:
- If the sample contains an odd number of items, the median is (n+1)/2-th element.
- If the sample contains an even number of elements, the median lies between the two middle elements of the sample and is equal to the arithmetic mean calculated over these two elements.
To calculate the median for a sample of 15 very high-risk mutual funds, we first need to sort the raw data (Figure 2). Then the median will be opposite the number of the middle element of the sample; in our example number 8. Excel has a special function =MEDIAN() that works with unordered arrays too.

Rice. 2. Median 15 funds
Thus, the median is 6.5. This means that half of the very high-risk funds do not exceed 6.5, while the other half do so. Note that the median of 6.5 is slightly larger than the median of 6.08.
If we remove the profitability of the RS Emerging Growth fund from the sample, then the median of the remaining 14 funds will decrease to 6.2%, that is, not as significantly as the arithmetic mean (Fig. 3).

Rice. 3. Median 14 funds
Fashion
The term was first introduced by Pearson in 1894. Fashion is the number that occurs most often in the sample (the most fashionable). Fashion describes well, for example, the typical reaction of drivers to a traffic signal to stop traffic. A classic example of the use of fashion is the choice of the size of the produced batch of shoes or the color of the wallpaper. If a distribution has multiple modes, then it is said to be multimodal or multimodal (has two or more "peaks"). The multimodal distribution provides important information about the nature of the variable under study. For example, in sociological surveys, if a variable represents a preference or attitude towards something, then multimodality could mean that there are several distinctly different opinions. Multimodality is also an indicator that the sample is not homogeneous and that the observations may be generated by two or more "overlapped" distributions. Unlike the arithmetic mean, outliers do not affect the mode. For continuously distributed random variables, such as the average annual returns of mutual funds, the mode sometimes does not exist at all (or does not make sense). Since these indicators can take on a variety of values, repeating values are extremely rare.
Quartiles
Quartiles are measures that are most commonly used to evaluate the distribution of data when describing the properties of large numerical samples. While the median splits the ordered array in half (50% of the array elements are less than the median and 50% are greater), quartiles break the ordered dataset into four parts. The Q 1 , median and Q 3 values are the 25th, 50th and 75th percentile, respectively. The first quartile Q 1 is a number that divides the sample into two parts: 25% of the elements are less than, and 75% are more than the first quartile.
The third quartile Q 3 is a number that also divides the sample into two parts: 75% of the elements are less than, and 25% are more than the third quartile.
To calculate quartiles in versions of Excel prior to 2007, the function =QUARTILE(array, part) was used. Starting with Excel 2010, two functions apply:
- =QUARTILE.ON(array, part)
- =QUARTILE.EXC(array, part)
These two functions give slightly different values (Figure 4). For example, when calculating the quartiles for a sample containing data on the average annual return of 15 very high-risk mutual funds, Q 1 = 1.8 or -0.7 for QUARTILE.INC and QUARTILE.EXC, respectively. By the way, the QUARTILE function used earlier corresponds to the modern QUARTILE.ON function. To calculate quartiles in Excel using the above formulas, the data array can be left unordered.

Rice. 4. Calculate quartiles in Excel
Let's emphasize again. Excel can calculate quartiles for univariate discrete series, containing the values of a random variable. The calculation of quartiles for a frequency-based distribution is given in the section below.
geometric mean
Unlike the arithmetic mean, the geometric mean measures how much a variable has changed over time. The geometric mean is the root n th degree from the product n values (in Excel, the function = CUGEOM is used):
G= (X 1 * X 2 * ... * X n) 1/n
A similar parameter - the geometric mean of the rate of return - is determined by the formula:
G \u003d [(1 + R 1) * (1 + R 2) * ... * (1 + R n)] 1 / n - 1,
Where R i- rate of return i-th period of time.
For example, suppose the initial investment is $100,000. By the end of the first year, it drops to $50,000, and by the end of the second year, it recovers to the original $100,000. The rate of return on this investment over a two-year period is equal to 0, since the initial and final amount of funds are equal to each other. However, the arithmetic average of annual rates of return is = (-0.5 + 1) / 2 = 0.25 or 25%, since the rate of return in the first year R 1 = (50,000 - 100,000) / 100,000 = -0.5 , and in the second R 2 = (100,000 - 50,000) / 50,000 = 1. At the same time, the geometric mean of the rate of return for two years is: G = [(1–0.5) * (1 + 1 )] 1/2 – 1 = ½ – 1 = 1 – 1 = 0. Thus, the geometric mean more accurately reflects the change (more precisely, the absence of change) in the volume of investments over the biennium than the arithmetic mean.
Interesting Facts. First, the geometric mean will always be less than the arithmetic mean of the same numbers. Except for the case when all the taken numbers are equal to each other. Secondly, having considered the properties of a right triangle, one can understand why the mean is called geometric. The height of a right-angled triangle, lowered to the hypotenuse, is the average proportional between the projections of the legs on the hypotenuse, and each leg is the average proportional between the hypotenuse and its projection on the hypotenuse (Fig. 5). This gives a geometric way of constructing the geometric mean of two (lengths) segments: you need to build a circle on the sum of these two segments as a diameter, then the height, restored from the point of their connection to the intersection with the circle, will give the required value:

Rice. 5. The geometric nature of the geometric mean (figure from Wikipedia)
The second important property of numerical data is their variation characterizing the degree of dispersion of the data. Two different samples can differ both in mean values and in variations. However, as shown in fig. 6 and 7, two samples can have the same variation but different means, or the same mean and completely different variation. The data corresponding to polygon B in Fig. 7 change much less than the data from which polygon A was built.

Rice. 6. Two symmetric bell-shaped distributions with the same spread and different mean values

Rice. 7. Two symmetric bell-shaped distributions with the same mean values and different scatter
There are five estimates of data variation:
- span,
- interquartile range,
- dispersion,
- standard deviation,
- the coefficient of variation.
scope
The range is the difference between the largest and smallest elements of the sample:
Swipe = XMax-XMin
The range of a sample containing data on the average annual returns of 15 very high-risk mutual funds can be calculated using an ordered array (see Figure 4): Range = 18.5 - (-6.1) = 24.6. This means that the difference between the highest and lowest average annual returns for very high risk funds is 24.6%.
The range measures the overall spread of the data. Although the sample range is a very simple estimate of the total spread of the data, its weakness is that it does not take into account exactly how the data is distributed between the minimum and maximum elements. This effect is well seen in Fig. 8 which illustrates samples having the same range. The B scale shows that if the sample contains at least one extreme value, the sample range is a very inaccurate estimate of the scatter of the data.

Rice. 8. Comparison of three samples with the same range; the triangle symbolizes the support of the balance, and its location corresponds to the average value of the sample
Interquartile range
The interquartile, or mean, range is the difference between the third and first quartiles of the sample:
Interquartile range \u003d Q 3 - Q 1
This value makes it possible to estimate the spread of 50% of the elements and not to take into account the influence of extreme elements. The interquartile range for a sample containing data on the average annual returns of 15 very high-risk mutual funds can be calculated using the data in Fig. 4 (for example, for the function QUARTILE.EXC): Interquartile range = 9.8 - (-0.7) = 10.5. The interval between 9.8 and -0.7 is often referred to as the middle half.
It should be noted that the Q 1 and Q 3 values, and hence the interquartile range, do not depend on the presence of outliers, since their calculation does not take into account any value that would be less than Q 1 or greater than Q 3 . The total quantitative characteristics, such as the median, the first and third quartiles, and the interquartile range, which are not affected by outliers, are called robust indicators.
While the range and interquartile range provide an estimate of the total and mean scatter of the sample, respectively, neither of these estimates takes into account exactly how the data are distributed. Variance and standard deviation free from this shortcoming. These indicators allow you to assess the degree of fluctuation of the data around the mean. Sample variance is an approximation of the arithmetic mean calculated from the squared differences between each sample element and the sample mean. For a sample of X 1 , X 2 , ... X n the sample variance (denoted by the symbol S 2 is given by the following formula:

In general, the sample variance is the sum of the squared differences between the sample elements and the sample mean, divided by a value equal to the sample size minus one:

Where - arithmetic mean, n- sample size, X i - i-th sample element X. In Excel before version 2007, the function =VAR() was used to calculate the sample variance, since version 2010, the function =VAR.V() is used.
The most practical and widely accepted estimate of data scatter is standard deviation. This indicator is denoted by the symbol S and is equal to the square root of the sample variance:

In Excel before version 2007, the =STDEV() function was used to calculate the standard deviation, from version 2010 the =STDEV.B() function is used. To calculate these functions, the data array can be unordered.
Neither the sample variance nor the sample standard deviation can be negative. The only situation in which the indicators S 2 and S can be zero is if all elements of the sample are equal. In this completely improbable case, the range and interquartile range are also zero.
Numeric data is inherently volatile. Any variable can take on many different values. For example, different mutual funds have different rates of return and loss. Due to the variability of numerical data, it is very important to study not only estimates of the mean, which are summative in nature, but also estimates of the variance, which characterize the scatter of the data.
The variance and standard deviation allow us to estimate the spread of data around the mean, in other words, to determine how many elements of the sample are less than the mean, and how many are greater. The dispersion has some valuable mathematical properties. However, its value is the square of a unit of measure - a square percentage, a square dollar, a square inch, etc. Therefore, a natural estimate of the variance is the standard deviation, which is expressed in the usual units of measurement - percent of income, dollars or inches.
The standard deviation allows you to estimate the amount of fluctuation of the sample elements around the mean value. In almost all situations, the majority of observed values lie within plus or minus one standard deviation from the mean. Therefore, knowing the arithmetic mean of the sample elements and the standard sample deviation, it is possible to determine the interval to which the bulk of the data belongs.
The standard deviation of returns on 15 very high-risk mutual funds is 6.6 (Figure 9). This means that the profitability of the bulk of funds differs from the average value by no more than 6.6% (i.e., it fluctuates in the range from – S= 6.2 – 6.6 = –0.4 to +S= 12.8). In fact, this interval contains a five-year average annual return of 53.3% (8 out of 15) of funds.

Rice. 9. Standard deviation
Note that in the process of summing the squared differences, items that are farther from the mean gain more weight than items that are closer. This property is the main reason why the arithmetic mean is most often used to estimate the mean of a distribution.
The coefficient of variation
Unlike previous scatter estimates, the coefficient of variation is a relative estimate. It is always measured as a percentage, not in the original data units. The coefficient of variation, denoted by the symbols CV, measures the scatter of the data around the mean. The coefficient of variation is equal to the standard deviation divided by the arithmetic mean and multiplied by 100%:

Where S- standard sample deviation, - sample mean.
The coefficient of variation allows you to compare two samples, the elements of which are expressed in different units of measurement. For example, the manager of a mail delivery service intends to upgrade the fleet of trucks. When loading packages, there are two types of restrictions to consider: the weight (in pounds) and the volume (in cubic feet) of each package. Assume that in a sample of 200 bags, the average weight is 26.0 pounds, the standard deviation of the weight is 3.9 pounds, the average package volume is 8.8 cubic feet, and the standard deviation of the volume is 2.2 cubic feet. How to compare the spread of weight and volume of packages?
Since the units of measurement for weight and volume differ from each other, the manager must compare the relative spread of these values. The weight variation coefficient is CV W = 3.9 / 26.0 * 100% = 15%, and the volume variation coefficient CV V = 2.2 / 8.8 * 100% = 25% . Thus, the relative scatter of packet volumes is much larger than the relative scatter of their weights.
Distribution form
The third important property of the sample is the form of its distribution. This distribution can be symmetrical or asymmetric. To describe the shape of a distribution, it is necessary to calculate its mean and median. If these two measures are the same, the variable is said to be symmetrically distributed. If the mean value of a variable is greater than the median, its distribution has a positive skewness (Fig. 10). If the median is greater than the mean, the distribution of the variable is negatively skewed. Positive skewness occurs when the mean increases to unusually high values. Negative skewness occurs when the mean decreases to unusually small values. A variable is symmetrically distributed if it does not take on any extreme values in either direction, such that large and small values of the variable cancel each other out.

Rice. 10. Three types of distributions
The data depicted on the A scale have a negative skewness. This figure shows a long tail and left skew caused by unusually small values. These extremely small values shift the mean value to the left, and it becomes less than the median. The data shown on scale B are distributed symmetrically. The left and right halves of the distribution are their mirror images. Large and small values balance each other, and the mean and median are equal. The data shown on scale B has a positive skewness. This figure shows a long tail and skew to the right, caused by the presence of unusually high values. These too large values shift the mean to the right, and it becomes larger than the median.
In Excel, descriptive statistics can be obtained using the add-in Analysis package. Go through the menu Data → Data analysis, in the window that opens, select the line Descriptive statistics and click Ok. In the window Descriptive statistics be sure to indicate input interval(Fig. 11). If you want to see descriptive statistics on the same sheet as the original data, select the radio button output interval and specify the cell where you want to place the upper left corner of the displayed statistics (in our example, $C$1). If you want to output data to a new sheet or to a new workbook, simply select the appropriate radio button. Check the box next to Final statistics. Optionally, you can also choose Difficulty level,k-th smallest andk-th largest.
If on deposit Data in area Analysis you don't see the icon Data analysis, you must first install the add-on Analysis package(see, for example,).

Rice. 11. Descriptive statistics of the five-year average annual returns of funds with very high levels of risk, calculated using the add-on Data analysis Excel programs
Excel calculates a number of statistics discussed above: mean, median, mode, standard deviation, variance, range ( interval), minimum, maximum, and sample size ( check). In addition, Excel calculates some new statistics for us: standard error, kurtosis, and skewness. standard error equals the standard deviation divided by the square root of the sample size. asymmetry characterizes the deviation from the symmetry of the distribution and is a function that depends on the cube of differences between the elements of the sample and the mean value. Kurtosis is a measure of the relative concentration of data around the mean versus the tails of the distribution, and depends on the differences between the sample and the mean raised to the fourth power.
Calculation of descriptive statistics for the general population
The mean, scatter, and shape of the distribution discussed above are sample-based characteristics. However, if the dataset contains numerical measurements of the entire population, then its parameters can be calculated. These parameters include the mean, variance, and standard deviation of the population.
Expected value is equal to the sum of all values of the general population divided by the volume of the general population:

Where µ - expected value, Xi- i-th variable observation X, N- the volume of the general population. In Excel, to calculate the mathematical expectation, the same function is used as for the arithmetic mean: =AVERAGE().
Population variance equal to the sum of the squared differences between the elements of the general population and mat. expectation divided by the size of the population:

Where σ2 is the variance of the general population. Excel prior to version 2007 uses the =VAR() function to calculate the population variance, starting with version 2010 =VAR.G().
population standard deviation is equal to the square root of the population variance:

Excel prior to version 2007 uses =STDEV() to calculate the population standard deviation, starting with version 2010 =STDEV.Y(). Note that the formulas for population variance and standard deviation are different from the formulas for sample variance and standard deviation. When calculating sample statistics S2 And S the denominator of the fraction is n - 1, and when calculating the parameters σ2 And σ - the volume of the general population N.
rule of thumb
In most situations, a large proportion of observations are concentrated around the median, forming a cluster. In data sets with positive skewness, this cluster is located to the left (i.e., below) the mathematical expectation, and in sets with negative skewness, this cluster is located to the right (i.e., above) of the mathematical expectation. Symmetric data have the same mean and median, and the observations cluster around the mean, forming a bell-shaped distribution. If the distribution does not have a pronounced skewness, and the data is concentrated around a certain center of gravity, a rule of thumb can be used to estimate variability, which says: if the data has a bell-shaped distribution, then approximately 68% of the observations are less than one standard deviation from the mathematical expectation, Approximately 95% of the observations are within two standard deviations of the expected value, and 99.7% of the observations are within three standard deviations of the expected value.
Thus, the standard deviation, which is an estimate of the average fluctuation around the mathematical expectation, helps to understand how the observations are distributed and to identify outliers. It follows from the rule of thumb that for bell-shaped distributions, only one value in twenty differs from the mathematical expectation by more than two standard deviations. Therefore, values outside the interval µ ± 2σ, can be considered outliers. In addition, only three out of 1000 observations differ from the mathematical expectation by more than three standard deviations. Thus, values outside the interval µ ± 3σ are almost always outliers. For distributions that are highly skewed or not bell-shaped, the Biename-Chebyshev rule of thumb can be applied.
More than a hundred years ago, the mathematicians Bienamay and Chebyshev independently discovered a useful property of the standard deviation. They found that for any data set, regardless of the shape of the distribution, the percentage of observations that lie at a distance not exceeding k standard deviations from mathematical expectation, not less (1 – 1/ 2)*100%.
For example, if k= 2, the Biename-Chebyshev rule states that at least (1 - (1/2) 2) x 100% = 75% of the observations must lie in the interval µ ± 2σ. This rule is true for any k exceeding one. The Biename-Chebyshev rule is of a very general nature and is valid for distributions of any kind. It indicates the minimum number of observations, the distance from which to the mathematical expectation does not exceed a given value. However, if the distribution is bell-shaped, the rule of thumb more accurately estimates the concentration of data around the mean.
Computing descriptive statistics for a frequency-based distribution
If the original data is not available, the frequency distribution becomes the only source of information. In such situations, you can calculate the approximate values of quantitative indicators of the distribution, such as the arithmetic mean, standard deviation, quartiles.
If the sample data is presented as a frequency distribution, an approximate value of the arithmetic mean can be calculated, assuming that all values within each class are concentrated at the midpoint of the class:

Where - sample mean, n- number of observations, or sample size, With- the number of classes in the frequency distribution, mj- middle point j-th class, fj- frequency corresponding to j-th class.
To calculate the standard deviation from the frequency distribution, it is also assumed that all values within each class are concentrated at the midpoint of the class.

To understand how the quartiles of the series are determined based on frequencies, let us consider the calculation of the lower quartile based on data for 2013 on the distribution of the Russian population by average per capita cash income (Fig. 12).

Rice. 12. The share of the population of Russia with per capita monetary income on average per month, rubles
To calculate the first quartile of the interval variation series, you can use the formula:

where Q1 is the value of the first quartile, xQ1 is the lower limit of the interval containing the first quartile (the interval is determined by the accumulated frequency, the first exceeding 25%); i is the value of the interval; Σf is the sum of the frequencies of the entire sample; probably always equal to 100%; SQ1–1 is the cumulative frequency of the interval preceding the interval containing the lower quartile; fQ1 is the frequency of the interval containing the lower quartile. The formula for the third quartile differs in that in all places, instead of Q1, you need to use Q3, and substitute ¾ instead of ¼.
In our example (Fig. 12), the lower quartile is in the range 7000.1 - 10,000, the cumulative frequency of which is 26.4%. The lower limit of this interval is 7000 rubles, the value of the interval is 3000 rubles, the accumulated frequency of the interval preceding the interval containing the lower quartile is 13.4%, the frequency of the interval containing the lower quartile is 13.0%. Thus: Q1 \u003d 7000 + 3000 * (¼ * 100 - 13.4) / 13 \u003d 9677 rubles.
Pitfalls associated with descriptive statistics
In this note, we looked at how to describe a dataset using various statistics that estimate its mean, scatter, and distribution. The next step is to analyze and interpret the data. So far, we have studied the objective properties of data, and now we turn to their subjective interpretation. Two mistakes lie in wait for the researcher: an incorrectly chosen subject of analysis and an incorrect interpretation of the results.
An analysis of the performance of 15 very high-risk mutual funds is fairly unbiased. He led to completely objective conclusions: all mutual funds have different returns, the spread of fund returns ranges from -6.1 to 18.5, and the average return is 6.08. The objectivity of data analysis is ensured by the correct choice of total quantitative indicators of the distribution. Several methods for estimating the mean and scatter of data were considered, and their advantages and disadvantages were indicated. How to choose the right statistics that provide an objective and unbiased analysis? If the data distribution is slightly skewed, should the median be chosen over the arithmetic mean? Which indicator more accurately characterizes the spread of data: standard deviation or range? Should the positive skewness of the distribution be indicated?
On the other hand, data interpretation is a subjective process. Different people come to different conclusions, interpreting the same results. Everyone has their own point of view. Someone considers the total average annual returns of 15 funds with a very high level of risk to be good and is quite satisfied with the income received. Others may think that these funds have too low returns. Thus, subjectivity should be compensated by honesty, neutrality and clarity of conclusions.
Ethical Issues
Data analysis is inextricably linked to ethical issues. One should be critical of the information disseminated by newspapers, radio, television and the Internet. Over time, you will learn to be skeptical not only about the results, but also about the goals, subject and objectivity of research. The famous British politician Benjamin Disraeli said it best: “There are three kinds of lies: lies, damned lies and statistics.”
As noted in the note, ethical issues arise when choosing the results that should be presented in the report. Both positive and negative results should be published. In addition, when making a report or written report, the results must be presented honestly, neutrally and objectively. Distinguish between bad and dishonest presentations. To do this, it is necessary to determine what the intentions of the speaker were. Sometimes the speaker omits important information out of ignorance, and sometimes deliberately (for example, if he uses the arithmetic mean to estimate the mean of clearly skewed data in order to get the desired result). It is also dishonest to suppress results that do not correspond to the point of view of the researcher.
Materials from the book Levin et al. Statistics for managers are used. - M.: Williams, 2004. - p. 178–209
QUARTILE function retained to align with earlier versions of Excel
Most of all in eq. In practice, one has to use the arithmetic mean, which can be calculated as the simple and weighted arithmetic mean.
Arithmetic mean (CA)-n the most common type of medium. It is used in cases where the volume of a variable attribute for the entire population is the sum of the values of the attributes of its individual units. Social phenomena are characterized by the additivity (summation) of the volumes of the varying attribute, this determines the scope of the SA and explains its prevalence as a generalizing indicator, for example: the general salary fund is the sum of the salary of all employees.
To calculate SA, you need to divide the sum of all feature values by their number. SA is used in 2 forms.
Consider first the simple arithmetic mean.
1-CA simple (initial, defining form) is equal to the simple sum of the individual values of the averaged feature, divided by the total number of these values (used when there are ungrouped index values of the feature):
The calculations made can be summarized in the following formula:
 (1)
(1)
Where  - the average value of the variable attribute, i.e., the simple arithmetic mean;
- the average value of the variable attribute, i.e., the simple arithmetic mean;
 means summation, i.e., the addition of individual features;
means summation, i.e., the addition of individual features;
x- individual values of a variable attribute, which are called variants;
n - number of population units
Example1, it is required to find the average output of one worker (locksmith), if it is known how many parts each of the 15 workers produced, i.e. given a number of ind. trait values, pcs.: 21; 20; 20; 19; 21; 19; 18; 22; 19; 20; 21; 20; 18; 19; 20.
SA simple is calculated by the formula (1), pcs.:
Example2. Let us calculate SA based on conditional data for 20 stores that are part of a trading company (Table 1). Table 1
Distribution of shops of the trading company "Vesna" by trading area, sq. M
|
store number |
store number | ||
To calculate the average store area ( 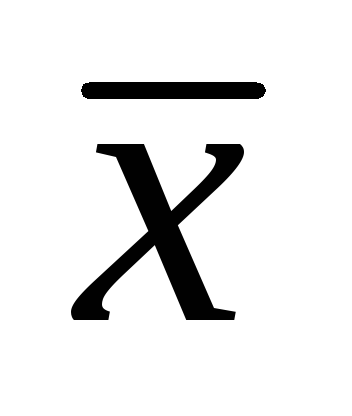 ) it is necessary to add up the areas of all stores and divide the result by the number of stores:
) it is necessary to add up the areas of all stores and divide the result by the number of stores:

Thus, the average store area for this group of trade enterprises is 71 sq.m.
Therefore, in order to determine the SA is simple, it is necessary to divide the sum of all values of a given attribute by the number of units that have this attribute.
2
Where f 1
,
f 2
,
… ,f n
–
weight (frequency of repetition of the same features); is the sum of the products of the magnitude of features and their frequencies; is the total number of population units.![]() (2)
(2)
Where X- options;
f- frequency (weight).
SA weighted is the quotient of dividing the sum of the products of the variants and their corresponding frequencies by the sum of all frequencies. Frequencies ( f) appearing in the SA formula are usually called scales, as a result of which the SA calculated taking into account the weights is called the weighted SA.
We will illustrate the technique for calculating weighted SA using the example 1 considered above. To do this, we group the initial data and place them in Table.
The average of the grouped data is determined as follows: first, the variants are multiplied by the frequencies, then the products are added and the resulting sum is divided by the sum of the frequencies.
According to formula (2), the weighted SA is, pcs.: ![]()

P

Distribution of Vesna stores by retail space, sq. m
Thus, the result is the same. However, this will already be the arithmetic weighted average.
In the previous example, we computed the arithmetic average, provided that the absolute frequencies (number of stores) are known. However, in some cases there are no absolute frequencies, but relative frequencies are known, or, as they are commonly called, frequencies that show the proportion or the proportion of frequencies in the entire population.
When calculating SA weighted use frequencies allows you to simplify calculations when the frequency is expressed in large, multi-digit numbers. The calculation is made in the same way, however, since the average value is increased by 100 times, the result should be divided by 100.
Then the formula for the arithmetic weighted average will look like:
Where d– frequency, i.e. the share of each frequency in the total sum of all frequencies.
(3)In our example 2, we first determine the share of stores by groups in the total number of stores of the company "Spring". So, for the first group, the specific gravity corresponds to 10%  . We get the following data Table3
. We get the following data Table3
Average values refer to generalizing statistical indicators that give a summary (final) characteristic of mass social phenomena, since they are built on the basis of a large number of individual values of a varying attribute. To clarify the essence of the average value, it is necessary to consider the features of the formation of the values of the signs of those phenomena, according to which the average value is calculated.
It is known that the units of each mass phenomenon have numerous features. Whichever of these signs we take, its values for individual units will be different, they change, or, as they say in statistics, vary from one unit to another. So, for example, the salary of an employee is determined by his qualifications, the nature of work, length of service and a number of other factors, and therefore varies over a very wide range. The cumulative influence of all factors determines the amount of earnings of each employee, however, we can talk about the average monthly wages of workers in different sectors of the economy. Here we operate with a typical, characteristic value of a variable attribute, referred to a unit of a large population.
The average reflects that general, which is typical for all units of the studied population. At the same time, it balances the influence of all factors acting on the magnitude of the attribute of individual units of the population, as if mutually canceling them. The level (or size) of any social phenomenon is determined by the action of two groups of factors. Some of them are general and main, constantly operating, closely related to the nature of the phenomenon or process being studied, and form that typical for all units of the studied population, which is reflected in the average value. Others are individual, their action is less pronounced and is episodic, random. They act in the opposite direction, cause differences between the quantitative characteristics of individual units of the population, seeking to change the constant value of the characteristics being studied. The action of individual signs is extinguished in the average value. In the cumulative influence of typical and individual factors, which is balanced and mutually canceled out in generalizing characteristics, the fundamental law of large numbers.
In the aggregate, the individual values of the signs merge into a common mass and, as it were, dissolve. Hence and average value acts as "impersonal", which can deviate from the individual values of features, not quantitatively coinciding with any of them. The average value reflects the general, characteristic and typical for the entire population due to the mutual cancellation in it of random, atypical differences between the signs of its individual units, since its value is determined, as it were, by the common resultant of all causes.
However, in order for the average value to reflect the most typical value of a trait, it should not be determined for any populations, but only for populations consisting of qualitatively homogeneous units. This requirement is the main condition for the scientifically based application of averages and implies a close connection between the method of averages and the method of groupings in the analysis of socio-economic phenomena. Therefore, the average value is a generalizing indicator that characterizes the typical level of a variable trait per unit of a homogeneous population in specific conditions of place and time.
Determining, thus, the essence of average values, it must be emphasized that the correct calculation of any average value implies the fulfillment of the following requirements:
- qualitative homogeneity of the population on which the average value is calculated. This means that the calculation of average values should be based on the grouping method, which ensures the selection of homogeneous, same-type phenomena;
- exclusion of the influence on the calculation of the average value of random, purely individual causes and factors. This is achieved when the calculation of the average is based on sufficiently massive material in which the operation of the law of large numbers is manifested, and all accidents cancel each other out;
- when calculating the average value, it is important to establish the purpose of its calculation and the so-called defining indicator-tel(property) to which it should be oriented.
The determining indicator can act as the sum of the values of the averaged attribute, the sum of its reciprocal values, the product of its values, etc. The relationship between the defining indicator and the average value is expressed as follows: if all values of the averaged attribute are replaced by the average value, then their sum or product in in this case will not change the defining indicator. On the basis of this connection of the determining indicator with the average value, an initial quantitative ratio is built for the direct calculation of the average value. The ability of averages to preserve the properties of statistical populations is called defining property.
The average value calculated for the population as a whole is called general average; average values calculated for each group - group averages. The general average reflects the general features of the phenomenon under study, the group average gives a description of the phenomenon that develops under the specific conditions of this group.
The calculation methods can be different, therefore, in statistics, several types of average are distinguished, the main of which are the arithmetic average, the harmonic average and the geometric average.
In economic analysis, the use of averages is the main tool for assessing the results of scientific and technological progress, social measures, and the search for reserves for economic development. At the same time, it should be remembered that excessive focus on averages can lead to biased conclusions when conducting economic and statistical analysis. This is due to the fact that average values, being generalizing indicators, cancel out and ignore those differences in the quantitative characteristics of individual units of the population that really exist and may be of independent interest.
Types of averages
In statistics, various types of averages are used, which are divided into two large classes:
- power averages (harmonic mean, geometric mean, arithmetic mean, mean square, mean cubic);
- structural averages (mode, median).
To calculate power means all available characteristic values must be used. Fashion And median are determined only by the distribution structure, therefore they are called structural, positional averages. The median and mode are often used as an average characteristic in those populations where the calculation of the mean exponential is impossible or impractical.
The most common type of average is the arithmetic average. Under arithmetic mean is understood as the value of a feature that each unit of the population would have if the total of all values of the feature were distributed evenly among all units of the population. The calculation of this value is reduced to the summation of all values of the variable attribute and the division of the resulting amount by the total number of population units. For example, five workers completed an order for the manufacture of parts, while the first produced 5 parts, the second - 7, the third - 4, the fourth - 10, the fifth - 12. Since the value of each option occurred only once in the initial data, to determine the average output of one worker should apply the simple arithmetic mean formula:
i.e., in our example, the average output of one worker is equal to

Along with the simple arithmetic mean, they study weighted arithmetic mean. For example, let's calculate the average age of students in a group of 20 people whose age ranges from 18 to 22 years old, where xi- variants of the averaged feature, fi- frequency, which shows how many times it occurs i-th value in the aggregate (Table 5.1).
Table 5.1
Average age of students
Applying the weighted arithmetic mean formula, we get:

There is a certain rule for choosing a weighted arithmetic average: if there is a series of data on two indicators, for one of which it is necessary to calculate
the average value, and at the same time, the numerical values \u200b\u200bof the denominator of its logical formula are known, and the values \u200b\u200bof the numerator are unknown, but can be found as a product of these indicators, then the average value should be calculated using the arithmetic weighted average formula.
In some cases, the nature of the initial statistical data is such that the calculation of the arithmetic mean loses its meaning and the only generalizing indicator can only be another type of average value - average harmonic. At present, the computational properties of the arithmetic mean have lost their relevance in the calculation of generalizing statistical indicators due to the widespread introduction of electronic computers. The average harmonic value, which is also simple and weighted, has acquired great practical importance. If the numerical values of the numerator of the logical formula are known, and the values of the denominator are unknown, but can be found as a private division of one indicator by another, then the average value is calculated by the weighted harmonic mean formula.
For example, let it be known that the car traveled the first 210 km at a speed of 70 km/h, and the remaining 150 km at a speed of 75 km/h. It is impossible to determine the average speed of the car throughout the entire journey of 360 km using the arithmetic mean formula. Since the options are the speeds in individual sections xj= 70 km/h and X2= 75 km/h, and weights (fi) are the corresponding segments of the path, then the products of options by weights will have neither physical nor economic meaning. In this case, it makes sense to divide the segments of the path into the corresponding speeds (options xi), i.e., the time spent on passing individual sections of the path (fi / xi). If the segments of the path are denoted by fi, then the entire path is expressed as Σfi, and the time spent on the entire path is expressed as Σ fi / xi , Then the average speed can be found as the quotient of the total distance divided by the total time spent:

In our example, we get:

If when using the average harmonic weight of all options (f) are equal, then instead of the weighted one, you can use simple (unweighted) harmonic mean:

where xi - individual options; n- the number of variants of the averaged feature. In the example with speed, a simple harmonic mean could be applied if the segments of the path traveled at different speeds were equal.
Any average value should be calculated so that when it replaces each variant of the averaged feature, the value of some final, generalizing indicator, which is associated with the averaged indicator, does not change. So, when replacing the actual speeds on individual sections of the path with their average value (average speed), the total distance should not change.
The form (formula) of the average value is determined by the nature (mechanism) of the relationship of this final indicator with the averaged one, therefore the final indicator, the value of which should not change when the options are replaced by their average value, is called defining indicator. To derive the average formula, you need to compose and solve an equation using the relationship of the averaged indicator with the determining one. This equation is constructed by replacing the variants of the averaged feature (indicator) with their average value.
In addition to the arithmetic mean and the harmonic mean, other types (forms) of the mean are also used in statistics. All of them are special cases. degree average. If we calculate all types of power-law averages for the same data, then the values
they will be the same, the rule applies here majorance medium. As the exponent of the mean increases, so does the mean itself. The most commonly used formulas in practical research for calculating various types of power mean values are presented in Table. 5.2.
Table 5.2

The geometric mean is applied when available. n growth factors, while the individual values of the trait are, as a rule, relative values of the dynamics, built in the form of chain values, as a ratio to the previous level of each level in the dynamics series. The average thus characterizes the average growth rate. geometric mean simple calculated by the formula

Formula geometric mean weighted has the following form:

The above formulas are identical, but one is applied at current coefficients or growth rates, and the second - at the absolute values of the levels of the series.
root mean square is used when calculating with the values of square functions, is used to measure the degree of fluctuation of the individual values of a trait around the arithmetic mean in the distribution series and is calculated by the formula

Mean square weighted calculated using a different formula:

Average cubic is used when calculating with the values of cubic functions and is calculated by the formula

weighted average cubic:

All the above average values can be represented as a general formula:

where is the average value; - individual value; n- the number of units of the studied population; k- exponent, which determines the type of average.
When using the same source data, the more k in the general power mean formula, the larger the mean value. It follows from this that there is a regular relationship between the values of power means:
The average values described above give a generalized idea of the population under study, and from this point of view, their theoretical, applied, and cognitive significance is indisputable. But it happens that the value of the average does not coincide with any of the really existing options, therefore, in addition to the averages considered, in statistical analysis it is advisable to use the values of specific options that occupy a well-defined position in an ordered (ranked) series of attribute values. Among these quantities, the most commonly used are structural, or descriptive, average- mode (Mo) and median (Me).
Fashion- the value of the trait that is most often found in this population. With regard to the variational series, the mode is the most frequently occurring value of the ranked series, i.e., the variant with the highest frequency. Fashion can be used to determine the most visited stores, the most common price for any product. It shows the size of the feature characteristic of a significant part of the population, and is determined by the formula

where x0 is the lower limit of the interval; h- interval value; fm- interval frequency; fm_ 1 - frequency of the previous interval; fm+ 1 - frequency of the next interval.
median the variant located in the center of the ranked row is called. The median divides the series into two equal parts in such a way that on both sides of it there is the same number of population units. At the same time, in one half of the population units, the value of the variable attribute is less than the median, in the other half it is greater than it. The median is used when examining an element whose value is greater than or equal to or simultaneously less than or equal to half of the elements of the distribution series. The median gives a general idea of where the values of the feature are concentrated, in other words, where is their center.
The descriptive nature of the median is manifested in the fact that it characterizes the quantitative boundary of the values of the varying attribute, which are possessed by half of the population units. The problem of finding the median for a discrete variational series is solved simply. If all units of the series are given serial numbers, then the serial number of the median variant is defined as (n + 1) / 2 with an odd number of members n. If the number of members of the series is an even number, then the median will be the average of two variants with serial numbers n/ 2 and n / 2 + 1.
When determining the median in interval variation series, the interval in which it is located (the median interval) is first determined. This interval is characterized by the fact that its accumulated sum of frequencies is equal to or exceeds half the sum of all frequencies of the series. The calculation of the median of the interval variation series is carried out according to the formula

Where X0- the lower limit of the interval; h- interval value; fm- interval frequency; f- the number of members of the series;
∫m-1 - the sum of the accumulated terms of the series preceding this one.
Along with the median, for a more complete characterization of the structure of the studied population, other values of options are used, which occupy a quite definite position in the ranked series. These include quartiles And deciles. Quartiles divide the series by the sum of frequencies into 4 equal parts, and deciles - into 10 equal parts. There are three quartiles and nine deciles.
The median and mode, in contrast to the arithmetic mean, do not extinguish individual differences in the values of a variable attribute and, therefore, are additional and very important characteristics of the statistical population. In practice, they are often used instead of the average or along with it. It is especially expedient to calculate the median and mode in those cases when the studied population contains a certain number of units with a very large or very small value of the variable attribute. These values of options, which are not very characteristic for the population, while affecting the value of the arithmetic mean, do not affect the values of the median and mode, which makes the latter very valuable indicators for economic and statistical analysis.
Variation indicators
The purpose of a statistical study is to identify the main properties and patterns of the studied statistical population. In the process of summary processing of statistical observation data, we build distribution lines. There are two types of distribution series - attributive and variational, depending on whether the attribute taken as the basis of the grouping is qualitative or quantitative.
variational called distribution series built on a quantitative basis. The values of quantitative characteristics for individual units of the population are not constant, more or less differ from each other. This difference in the value of a trait is called variations. Separate numerical values of the trait occurring in the studied population are called value options. The presence of variation in individual units of the population is due to the influence of a large number of factors on the formation of the trait level. The study of the nature and degree of variation of signs in individual units of the population is the most important issue of any statistical study. Variation indicators are used to describe the measure of trait variability.
Another important task of statistical research is to determine the role of individual factors or their groups in the variation of certain features of the population. To solve such a problem in statistics, special methods for studying variation are used, based on the use of a system of indicators that measure variation. In practice, the researcher is faced with a sufficiently large number of options for the values of the attribute, which does not give an idea of the distribution of units according to the value of the attribute in the aggregate. To do this, all variants of the attribute values are arranged in ascending or descending order. This process is called row ranking. The ranked series immediately gives a general idea of the values that the feature takes in the aggregate.
The insufficiency of the average value for an exhaustive characterization of the population makes it necessary to supplement the average values with indicators that make it possible to assess the typicality of these averages by measuring the fluctuation (variation) of the trait under study. The use of these indicators of variation makes it possible to make the statistical analysis more complete and meaningful, and thus to better understand the essence of the studied social phenomena.
The simplest signs of variation are minimum And maximum - this is the smallest and largest value of the feature in the population. The number of repetitions of individual variants of feature values is called repetition rate. Let us denote the frequency of repetition of the feature value fi, the sum of frequencies equal to the volume of the studied population will be:
Where k- number of variants of attribute values. It is convenient to replace frequencies with frequencies - w.i. Frequency- relative frequency indicator - can be expressed in fractions of a unit or a percentage and allows you to compare variation series with a different number of observations. Formally we have:

To measure the variation of a trait, various absolute and relative indicators are used. The absolute indicators of variation include the mean linear deviation, the range of variation, variance, standard deviation.
Span variation(R) is the difference between the maximum and minimum values of the trait in the studied population: R= Xmax - Xmin. This indicator gives only the most general idea of the fluctuation of the trait under study, as it shows the difference only between the limiting values of the options. It is completely unrelated to the frequencies in the variational series, i.e., to the nature of the distribution, and its dependence can give it an unstable, random character only from the extreme values of the attribute. The range of variation does not provide any information about the features of the studied populations and does not allow us to assess the degree of typicality of the obtained average values. The scope of this indicator is limited to fairly homogeneous populations, more precisely, it characterizes the variation of a trait, an indicator based on taking into account the variability of all values of the trait.
To characterize the variation of a trait, it is necessary to generalize the deviations of all values from any value typical for the population under study. Such indicators
variations, such as the mean linear deviation, variance and standard deviation, are based on the consideration of deviations of the values of the attribute of individual units of the population from the arithmetic mean.
Average linear deviation is the arithmetic mean of the absolute values of the deviations of individual options from their arithmetic mean:

The absolute value (modulus) of the variant deviation from the arithmetic mean; f- frequency.
The first formula is applied if each of the options occurs in the aggregate only once, and the second - in series with unequal frequencies.
There is another way to average the deviations of options from the arithmetic mean. This method, which is very common in statistics, is reduced to calculating the squared deviations of options from the mean value and then averaging them. In this case, we get a new indicator of variation - the variance.
Dispersion(σ 2) - the average of the squared deviations of the variants of the trait values from their average value:

The second formula is used if the variants have their own weights (or frequencies of the variation series).
In economic and statistical analysis, it is customary to evaluate the variation of an attribute most often using the standard deviation. Standard deviation(σ) is the square root of the variance:

The mean linear and mean square deviations show how much the value of the attribute fluctuates on average for the units of the population under study, and are expressed in the same units as the variants.
In statistical practice, it often becomes necessary to compare the variation of various features. For example, it is of great interest to compare variations in the age of personnel and their qualifications, length of service and wages, etc. For such comparisons, indicators of the absolute variability of signs - the average linear and standard deviation - are not suitable. It is impossible, in fact, to compare the fluctuation of work experience, expressed in years, with the fluctuation of wages, expressed in rubles and kopecks.
When comparing the variability of various traits in the aggregate, it is convenient to use relative indicators of variation. These indicators are calculated as the ratio of absolute indicators to the arithmetic mean (or median). Using as an absolute indicator of variation the range of variation, the average linear deviation, the standard deviation, one obtains the relative indicators of fluctuation:

The most commonly used indicator of relative volatility, characterizing the homogeneity of the population. The set is considered homogeneous if the coefficient of variation does not exceed 33% for distributions close to normal.
Topic 5. Averages as statistical indicators
The concept of average. Scope of average values in a statistical study
Average values are used at the stage of processing and summarizing the obtained primary statistical data. The need to determine the average values is due to the fact that for different units of the studied populations, the individual values of the same trait, as a rule, are not the same.
Average value call an indicator that characterizes the generalized value of a feature or a group of features in the study population.
If a population with qualitatively homogeneous characteristics is being studied, then the average value appears here as typical average. For example, for groups of workers in a certain industry with a fixed level of income, a typical average spending on basic necessities is determined, i.e. the typical average generalizes the qualitatively homogeneous values of the attribute in the given population, which is the share of expenditures of workers in this group on essential goods.
In the study of a population with qualitatively heterogeneous characteristics, the atypical average indicators may come to the fore. Such, for example, are the average indicators of the produced national income per capita (different age groups), the average yields of grain crops throughout Russia (areas of different climatic zones and different grain crops), the average birth rates of the population in all regions of the country, the average temperature for a certain period, etc. Here, average values generalize qualitatively heterogeneous values of features or systemic spatial aggregates (international community, continent, state, region, district, etc.) or dynamic aggregates extended in time (century, decade, year, season, etc.) . These averages are called system averages.
Thus, the meaning of average values consists in their generalizing function. The average value replaces a large number of individual values of a trait, revealing common properties inherent in all units of the population. This, in turn, makes it possible to avoid random causes and to identify common patterns due to common causes.
Types of average values and methods for their calculation
At the stage of statistical processing, a variety of research tasks can be set, for the solution of which it is necessary to choose the appropriate average. In this case, it is necessary to be guided by the following rule: the values \u200b\u200bthat represent the numerator and denominator of the average must be logically related to each other.
power averages;
structural averages.
Let us introduce the following notation:
The values for which the average is calculated;
Average, where the line above indicates that the averaging of individual values takes place;
Frequency (repeatability of individual trait values).
Various means are derived from the general power mean formula:
 (5.1)
(5.1)
for k = 1 - arithmetic mean; k = -1 - harmonic mean; k = 0 - geometric mean; k = -2 - root mean square.
Averages are either simple or weighted. weighted averages are called quantities that take into account that some variants of the values of the attribute may have different numbers, and therefore each variant has to be multiplied by this number. In other words, the "weights" are the numbers of population units in different groups, i.e. each option is "weighted" by its frequency. The frequency f is called statistical weight or weight average.
Arithmetic mean- the most common type of medium. It is used when the calculation is carried out on ungrouped statistical data, where you want to get the average summand. The arithmetic mean is such an average value of a feature, upon receipt of which the total volume of the feature in the population remains unchanged.
The arithmetic mean formula (simple) has the form
where n is the population size.
For example, the average salary of employees of an enterprise is calculated as the arithmetic average:

The determining indicators here are the wages of each employee and the number of employees of the enterprise. When calculating the average, the total amount of wages remained the same, but distributed, as it were, equally among all workers. For example, it is necessary to calculate the average salary of employees of a small company where 8 people are employed:
When calculating averages, individual values of the attribute that is averaged can be repeated, so the average is calculated using grouped data. In this case, we are talking about using arithmetic mean weighted, which looks like
 (5.3)
(5.3)
So, we need to calculate the average share price of a joint-stock company at the stock exchange. It is known that transactions were carried out within 5 days (5 transactions), the number of shares sold at the sales rate was distributed as follows:
1 - 800 ac. - 1010 rubles
2 - 650 ac. - 990 rub.
3 - 700 ak. - 1015 rubles.
4 - 550 ac. - 900 rub.
5 - 850 ak. - 1150 rubles.
The initial ratio for determining the average share price is the ratio of the total amount of transactions (TCA) to the number of shares sold (KPA):
OSS = 1010 800+990 650+1015 700+900 550+1150 850= 3 634 500;
CPA = 800+650+700+550+850=3550.
In this case, the average share price was equal to
It is necessary to know the properties of the arithmetic mean, which is very important both for its use and for its calculation. There are three main properties that most of all led to the widespread use of the arithmetic mean in statistical and economic calculations.
Property one (zero): the sum of positive deviations of the individual values of the trait from its mean value is equal to the sum of negative deviations. This is a very important property, since it shows that any deviations (both with + and with -) due to random causes will be mutually canceled.
Proof:

The second property (minimum): the sum of the squared deviations of the individual values of the attribute from the arithmetic mean is less than from any other number (a), i.e. is the minimum number.
Proof.
Compose the sum of the squared deviations from the variable a:
 (5.4)
(5.4)
To find the extremum of this function, it is necessary to equate its derivative with respect to a to zero:

From here we get:

 (5.5)
(5.5)
Therefore, the extremum of the sum of squared deviations is reached at . This extremum is the minimum, since the function cannot have a maximum.
Third property: the arithmetic mean of a constant is equal to this constant: at a = const.
In addition to these three most important properties of the arithmetic mean, there are so-called design properties, which are gradually losing their significance due to the use of electronic computers:
if the individual value of the attribute of each unit is multiplied or divided by a constant number, then the arithmetic mean will increase or decrease by the same amount;
the arithmetic mean will not change if the weight (frequency) of each feature value is divided by a constant number;
if the individual values of the attribute of each unit are reduced or increased by the same amount, then the arithmetic mean will decrease or increase by the same amount.
Average harmonic. This average is called the inverse arithmetic average, since this value is used when k = -1.
Simple harmonic mean is used when the weights of the characteristic values are the same. Its formula can be derived from the base formula by substituting k = -1:
For example, we need to calculate the average speed of two cars that have traveled the same path, but at different speeds: the first at 100 km/h, the second at 90 km/h. Using the harmonic mean method, we calculate the average speed:

In statistical practice, harmonic weighted is more often used, the formula of which has the form
This formula is used in cases where the weights (or volumes of phenomena) for each attribute are not equal. In the original ratio, the numerator is known to calculate the average, but the denominator is unknown.
In mathematics and statistics average arithmetic (or easily average) of a set of numbers is the sum of all the numbers in that set divided by their number. The arithmetic mean is a particularly general and most common representation of the average.
You will need
- Knowledge in mathematics.
Instruction
1. Let a set of four numbers be given. Need to discover average meaning this kit. To do this, we first find the sum of all these numbers. These numbers are possible 1, 3, 8, 7. Their sum is equal to S = 1 + 3 + 8 + 7 = 19. The set of numbers must consist of numbers of the same sign, otherwise the sense in calculating the average value is lost.
2. Average meaning set of numbers is equal to the sum of the numbers S divided by the number of these numbers. That is, it turns out that average meaning equals: 19/4 = 4.75.
3. For a set of numbers, it is also possible to detect not only average arithmetic, but average geometric. The geometric mean of several regular real numbers is a number that is allowed to replace any of these numbers so that their product does not change. The geometric mean G is sought by the formula: the root of the Nth degree of the product of a set of numbers, where N is the number of the number in the set. Let's look at the same set of numbers: 1, 3, 8, 7. Let's find them average geometric. To do this, we calculate the product: 1 * 3 * 8 * 7 = 168. Now from the number 168 you need to extract the root of the 4th degree: G = (168) ^ 1/4 = 3.61. Thus average the geometric set of numbers is 3.61.
Average the geometric mean is used less frequently than the arithmetic mean, but it can be useful in calculating the average value of indicators that change over time (the salary of an individual employee, the dynamics of academic performance, etc.).

You will need
- Engineering Calculator
Instruction
1. In order to find the geometric mean of a series of numbers, you first need to multiply all these numbers. Let's say you are given a set of five indicators: 12, 3, 6, 9 and 4. Let's multiply all these numbers: 12x3x6x9x4 = 7776.
2. Now from the resulting number it is necessary to extract the root of the degree equal to the number of elements of the series. In our case, from the number 7776, it will be necessary to extract the fifth root using an engineering calculator. The number obtained after this operation - in this case, the number 6 - will be the geometric mean for the initial group of numbers.
3. If you don’t have an engineering calculator at hand, then you can calculate the geometric mean of a series of numbers with support for the CPGEOM function in Excel or using one of the online calculators that are deliberately prepared for calculating geometric mean values.
Note!
If you need to find the geometric mean of each for 2 numbers, then you do not need an engineering calculator: you can extract the 2nd degree root (square root) from any number using the most ordinary calculator.
Helpful advice
In contrast to the arithmetic mean, the geometric mean is not so powerfully influenced by huge deviations and fluctuations between individual values in the studied set of indicators.
Average value is one of the collations of a set of numbers. Represents a number that cannot be outside the range defined by the largest and smallest values in this set of numbers. Average an arithmetic value is a particularly commonly used variety of averages.

Instruction
1. Add all the numbers in the set and divide them by the number of terms to get the arithmetic mean. Depending on certain calculation conditions, it is sometimes easier to divide any of the numbers by the number of values of the set and sum up the total.
2. Use, say, the calculator included with Windows OS, if calculating the arithmetic mean in your head is not possible. It can be opened with the support of the program launch dialog. To do this, press the "burning keys" WIN + R or click the "Start" button and select the "Run" command from the main menu. After that, type in the input field calc and press Enter on the keyboard or click the "OK" button. The same can be done through the main menu - open it, go to the "All Programs" section and to the "Typical" segments and select the "Calculator" line.
3. Enter all the numbers in the set in steps by pressing the Plus key on the keyboard after all of them (besides the last one) or by clicking the corresponding button in the calculator interface. Entering numbers is also allowed both from the keyboard and by clicking the corresponding interface buttons.
4. Press the slash key or click this icon in the calculator interface after entering the last set value and type the number of numbers in the sequence. Then press the equal sign and the calculator will calculate and display the arithmetic mean.
5. It is allowed to use the spreadsheet editor Microsoft Excel for the same purpose. In this case, start the editor and enter all the values of the sequence of numbers into adjacent cells. If, after entering the entire number, you press Enter or the down or right arrow key, the editor itself will move the input focus to the adjacent cell.
6. Select all the entered values and in the lower left corner of the editor window (in the status bar) you will see the arithmetic mean for the selected cells.
7. Click the cell next to the last number you entered if you'd rather just see the arithmetic mean. Expand the drop-down list with the image of the Greek letter sigma (Σ) in the "Editing" group of commands on the "Basic" tab. Select the line " Average” and the editor will insert the necessary formula for calculating the arithmetic mean in the selected cell. Press the Enter key and the value will be calculated.
The arithmetic mean is one of the measures of central propensity, widely used in mathematics and statistical calculations. Finding the arithmetic mean for several values is very easy, but every task has its own nuances, which you need to know in order to perform correct calculations.

What is the arithmetic mean
The arithmetic mean determines the average value for each initial array of numbers. In other words, from a certain set of numbers, a value that is universal for all elements is selected, the mathematical comparison of which with all elements is approximately equal. The arithmetic mean is preferably used when compiling financial and statistical reports or for calculating the quantitative results of similar skills performed.
How to find the arithmetic mean
The search for the arithmetic mean for an array of numbers should begin with determining the algebraic sum of these values. For example, if the array contains the numbers 23, 43, 10, 74 and 34, then their algebraic sum will be 184. When writing, the arithmetic mean is denoted by the letter? (mu) or x (x with a dash). Next, the algebraic sum should be divided by the number of numbers in the array. In this example, there were five numbers, so the arithmetic mean will be 184/5 and will be 36.8.
Features of working with negative numbers
If the array contains negative numbers, then the arithmetic mean is found using a similar algorithm. There is a difference only when calculating in the programming environment, or if there is additional data in the task. In these cases, finding the arithmetic mean of numbers with different signs comes down to three steps: 1. Finding the general arithmetic mean in the standard way; 2. Finding the arithmetic mean of negative numbers.3. Calculation of the arithmetic mean of positive numbers. The results of any of the actions are written separated by commas.
Natural and decimal fractions
If the array of numbers is represented by decimal fractions, the solution occurs according to the method of calculating the arithmetic mean of integers, but the total is reduced according to the requirements of the problem for the accuracy of the result. When working with natural fractions, they should be reduced to a common denominator, the one that is multiplied by the number of numbers in the array. The numerator of the result will be the sum of the reduced numerators of the initial fractional elements.
The geometric mean of numbers depends not only on the absolute value of the numbers themselves, but also on their number. It is impossible to confuse the geometric mean and the arithmetic mean of numbers, because they are found according to different methodologies. The geometric mean is invariably less than or equal to the arithmetic mean.

You will need
- Engineering calculator.
Instruction
1. Consider that in the general case the geometric mean of numbers is found by multiplying these numbers and extracting from them the root of the degree that corresponds to the number of numbers. Say, if you need to find the geometric mean of five numbers, then from the product it will be necessary to extract the root of the fifth degree.
2. To find the geometric mean of 2 numbers, use the basic rule. Find their product, then extract the square root from it, from the fact that the number is two, which corresponds to the degree of the root. Let's say, in order to find the geometric mean of the numbers 16 and 4, find their product 16 4=64. From the resulting number, extract the square root? 64 = 8. This will be the desired value. Please note that the arithmetic mean of these 2 numbers is larger and equals 10. If the root is not taken completely, round the total to the desired order.
3. In order to find the geometric mean of more than 2 numbers, also use the basic rule. To do this, find the product of all the numbers for which you need to find the geometric mean. From the resulting product, extract the root of the degree equal to the number of numbers. Let's say, in order to find the geometric mean of the numbers 2, 4 and 64, find their product. 2 4 64=512. From the fact that it is necessary to find the total of the geometric mean of 3 numbers, that extract the root of the third degree from the product. It is difficult to do this verbally, so use an engineering calculator. To do this, it has a button “x^y”. Dial the number 512, press the “x^y” button, then dial the number 3 and press the “1/x” button, to find the value 1/3, press the “=” button. We get the result of raising 512 to the power of 1/3, which corresponds to the root of the third degree. Get 512^1/3=8. This is the geometric mean of the numbers 2.4 and 64.
4. With the support of an engineering calculator, it is possible to detect the geometric mean using a different method. Find the log button on the keyboard. After that, take the logarithm of all of the numbers, find their sum, and divide it by the number of numbers. From the resulting number, take the antilogarithm. This will be the geometric mean of the numbers. Let's say, in order to find the geometric mean of the same numbers 2, 4 and 64, make a set of operations on the calculator. Dial the number 2, then press the log button, press the “+” button, dial the number 4 and press log and “+” again, dial 64, press log and “=”. The result will be a number equal to the sum of the decimal logarithms of the numbers 2, 4 and 64. Divide the resulting number by 3, from the fact that this is the number of numbers by which the geometric mean is sought. From the total, take the antilogarithm by toggling the register button and use the same log key. The result will be the number 8, this is the desired geometric mean.
Note!
The average value cannot be larger than the largest number in the set and smaller than the smallest.
Helpful advice
In mathematical statistics, the average value of a quantity is called the mathematical expectation.