W większości przypadków dane koncentrują się wokół jakiegoś centralnego punktu. Zatem, aby opisać dowolny zbiór danych, wystarczy wskazać wartość średnią. Rozważ kolejno trzy charakterystyki liczbowe, które służą do oszacowania średniej wartości rozkładu: średnią arytmetyczną, medianę i modę.
Przeciętny
Średnia arytmetyczna (często nazywana po prostu średnią) jest najczęstszym oszacowaniem średniej rozkładu. Jest wynikiem podzielenia sumy wszystkich zaobserwowanych wartości liczbowych przez ich liczbę. Dla próbki liczb X 1, X 2, ..., Xn, średnia próbki (oznaczona symbolem ) równa się \u003d (X 1 + X 2 + ... + Xn) / n, lub
gdzie jest średnia próbki, n- wielkość próbki, Xja– i-ty element próbki.
Pobierz notatkę w formacie lub, przykłady w formacie
Rozważ obliczenie średniej arytmetycznej pięcioletnich średnich rocznych stóp zwrotu 15 funduszy inwestycyjnych bardzo wysokiego ryzyka (Rysunek 1).

Ryż. 1. Średnia roczna stopa zwrotu z 15 funduszy inwestycyjnych bardzo wysokiego ryzyka
Średnią próbki oblicza się w następujący sposób:

Jest to dobry zwrot, zwłaszcza w porównaniu z 3-4% zwrotem, jaki deponenci banków lub kas oszczędnościowych uzyskali w tym samym okresie. Jeśli posortujemy wartości zwrotów, łatwo zauważyć, że osiem funduszy ma zwrot powyżej, a siedem poniżej średniej. Średnia arytmetyczna działa jak punkt równowagi, dzięki czemu fundusze o niskich dochodach równoważą fundusze o wysokich dochodach. Wszystkie elementy próby biorą udział w obliczaniu średniej. Żaden z pozostałych estymatorów średniej dystrybucji nie ma tej właściwości.
Kiedy obliczać średnią arytmetyczną. Ponieważ średnia arytmetyczna zależy od wszystkich elementów próbki, obecność wartości ekstremalnych znacząco wpływa na wynik. W takich sytuacjach średnia arytmetyczna może zniekształcić znaczenie danych liczbowych. Dlatego przy opisie zbioru danych zawierającego wartości ekstremalne konieczne jest wskazanie mediany lub średniej arytmetycznej i mediany. Na przykład, jeśli z próby usunie się zwrot z funduszu RS Emerging Growth, średnia z próby dla 14 funduszy spada o prawie 1% do 5,19%.
Mediana
Mediana jest środkową wartością uporządkowanej tablicy liczb. Jeśli tablica nie zawiera powtarzających się liczb, to połowa jej elementów będzie mniejsza i połowa większa niż mediana. Jeśli próbka zawiera wartości ekstremalne, do oszacowania średniej lepiej jest użyć mediany niż średniej arytmetycznej. Aby obliczyć medianę próbki, należy ją najpierw posortować.
Ta formuła jest niejednoznaczna. Jego wynik zależy od tego, czy liczba jest parzysta, czy nieparzysta. n:
- Jeśli próbka zawiera nieparzystą liczbę pozycji, mediana wynosi (n+1)/2-ty element.
- Jeżeli próba zawiera parzystą liczbę elementów, mediana leży między dwoma środkowymi elementami próby i jest równa średniej arytmetycznej obliczonej dla tych dwóch elementów.
Aby obliczyć medianę dla próby 15 funduszy inwestycyjnych o bardzo wysokim ryzyku, musimy najpierw posortować surowe dane (Rysunek 2). Wtedy mediana będzie naprzeciw numeru środkowego elementu próbki; w naszym przykładzie numer 8. Excel ma specjalną funkcję =MEDIAN(), która działa również z nieuporządkowanymi tablicami.

Ryż. 2. Mediana 15 funduszy
Zatem mediana wynosi 6,5. Oznacza to, że połowa funduszy bardzo wysokiego ryzyka nie przekracza 6,5, a druga połowa tak. Należy zauważyć, że mediana 6,5 jest nieco większa niż mediana 6,08.
Jeśli usuniemy z próby rentowność funduszu RS Emerging Growth, to mediana pozostałych 14 funduszy spadnie do 6,2%, czyli nie tak znacząco jak średnia arytmetyczna (rys. 3).

Ryż. 3. Mediana 14 funduszy
Moda
Termin ten został po raz pierwszy wprowadzony przez Pearsona w 1894 roku. Moda to liczba, która występuje najczęściej w próbie (najmodniejsza). Moda dobrze opisuje np. typową reakcję kierowców na sygnalizację świetlną nakazującą zatrzymanie ruchu. Klasycznym przykładem wykorzystania mody jest wybór rozmiaru produkowanej partii butów czy koloru tapety. Jeśli dystrybucja ma wiele modów, mówi się, że jest multimodalna lub multimodalna (ma dwa lub więcej „szczytów”). Rozkład multimodalny dostarcza ważnych informacji o naturze badanej zmiennej. Na przykład w badaniach socjologicznych, jeśli zmienna reprezentuje preferencje lub stosunek do czegoś, wówczas multimodalność może oznaczać, że istnieje kilka wyraźnie różnych opinii. Multimodalność jest również wskaźnikiem, że próba nie jest jednorodna i że obserwacje mogą być generowane przez dwa lub więcej „nakładających się” rozkładów. W przeciwieństwie do średniej arytmetycznej wartości odstające nie wpływają na tryb. W przypadku zmiennych losowych o rozkładzie ciągłym, takich jak średnie roczne stopy zwrotu z funduszy inwestycyjnych, tryb czasami w ogóle nie istnieje (lub nie ma sensu). Ponieważ wskaźniki te mogą przyjmować różne wartości, powtarzające się wartości są niezwykle rzadkie.
kwartyle
Kwartyle to miary najczęściej używane do oceny rozkładu danych przy opisywaniu właściwości dużych próbek liczbowych. Podczas gdy mediana dzieli uporządkowaną tablicę na pół (50% elementów tablicy jest mniejszych niż mediana, a 50% jest większych), kwartyle dzielą uporządkowany zbiór danych na cztery części. Wartości Q 1 , mediana i Q 3 to odpowiednio 25, 50 i 75 percentyl. Pierwszy kwartyl Q 1 to liczba, która dzieli próbę na dwie części: 25% elementów jest mniejszych niż pierwszy kwartyl, a 75% jest większych niż pierwszy kwartyl.
Trzeci kwartyl Q 3 to liczba, która również dzieli próbę na dwie części: 75% elementów jest mniejszych niż trzeci kwartyl, a 25% jest większych niż trzeci kwartyl.
Aby obliczyć kwartyle w wersjach programu Excel wcześniejszych niż 2007, użyto funkcji =QUARTILE(tablica; część). Począwszy od programu Excel 2010 mają zastosowanie dwie funkcje:
- =KWARTYL.ON(tablica; część)
- =KWARTYL.PRZEK(tablica;część)
Te dwie funkcje dają nieco inne wartości (Rysunek 4). Na przykład podczas obliczania kwartyli próby zawierającej dane dotyczące średniego rocznego zwrotu z 15 funduszy wspólnego inwestowania bardzo wysokiego ryzyka, Q 1 = 1,8 lub -0,7 odpowiednio dla QUARTIL.INC i QUARTIL.EXC. Nawiasem mówiąc, używana wcześniej funkcja KWARTYL odpowiada współczesnej funkcji KWARTYL.WŁ. Aby obliczyć kwartyle w programie Excel przy użyciu powyższych formuł, tablicę danych można pozostawić nieuporządkowaną.

Ryż. 4. Oblicz kwartyle w Excelu
Podkreślmy jeszcze raz. Excel może obliczyć kwartyle dla jednej zmiennej szereg dyskretny, zawierające wartości zmiennej losowej. Obliczanie kwartyli dla rozkładu opartego na częstotliwości podano w poniższej sekcji.
Średnia geometryczna
W przeciwieństwie do średniej arytmetycznej, średnia geometryczna mierzy, jak bardzo zmienna zmieniła się w czasie. Średnia geometryczna to pierwiastek n stopnia od produktu n wartości (w Excelu używana jest funkcja = CUGEOM):
G= (X 1 * X 2 * ... * X n) 1/n
Podobny parametr – średnią geometryczną stopy zwrotu – określa wzór:
G \u003d [(1 + R 1) * (1 + R 2) * ... * (1 + R n)] 1 / n - 1,
gdzie R ja- stopa zwrotu ja-ty okres czasu.
Załóżmy na przykład, że początkowa inwestycja wynosi 100 000 USD. Pod koniec pierwszego roku spada do 50 000 USD, a pod koniec drugiego roku wraca do pierwotnej wartości 100 000 USD. Stopa zwrotu z tej inwestycji w ciągu dwóch lat okres roku jest równy 0, ponieważ początkowa i końcowa kwota środków są sobie równe. Natomiast średnia arytmetyczna rocznych stóp zwrotu wynosi = (-0,5 + 1) / 2 = 0,25 czyli 25%, gdyż stopa zwrotu w pierwszym roku R 1 = (50 000 - 100 000) / 100 000 = -0,5 , a w drugim R 2 = (100 000 - 50 000) / 50 000 = 1. Jednocześnie średnia geometryczna stopy zwrotu za dwa lata wynosi: G = [(1–0,5) * (1 + 1 )] 1 /2 – 1 = ½ – 1 = 1 – 1 = 0. Zatem średnia geometryczna dokładniej odzwierciedla zmianę (dokładniej brak zmiany) wolumenu inwestycji w okresie dwuletnim niż średnia arytmetyczna.
Interesujące fakty. Po pierwsze, średnia geometryczna będzie zawsze mniejsza niż średnia arytmetyczna tych samych liczb. Z wyjątkiem przypadku, gdy wszystkie wzięte liczby są sobie równe. Po drugie, biorąc pod uwagę właściwości trójkąta prostokątnego, można zrozumieć, dlaczego średnią nazywa się geometryczną. Wysokość trójkąta prostokątnego, obniżonego do przeciwprostokątnej, jest średnią proporcjonalną między rzutami nóg na przeciwprostokątną, a każda noga jest średnią proporcjonalną między przeciwprostokątną a jej rzutem na przeciwprostokątną (ryc. 5). Daje to geometryczny sposób konstruowania średniej geometrycznej dwóch (długości) odcinków: trzeba zbudować okrąg na sumie tych dwóch odcinków jako średnicę, następnie wysokość, przywróconą od punktu ich połączenia do przecięcia z kółko, poda wymaganą wartość:

Ryż. 5. Geometryczny charakter średniej geometrycznej (rysunek z Wikipedii)
Drugą ważną właściwością danych liczbowych jest ich zmiana charakteryzujący stopień rozproszenia danych. Dwie różne próbki mogą różnić się zarówno wartościami średnimi, jak i odmianami. Jednakże, jak pokazano na ryc. 6 i 7, dwie próbki mogą mieć tę samą zmienność, ale różne średnie, lub tę samą średnią i zupełnie inną zmienność. Dane odpowiadające wielokątowi B na ryc. 7 zmieniają się znacznie mniej niż dane, z których zbudowano wielokąt A.

Ryż. 6. Dwa symetryczne rozkłady dzwonowe o tym samym rozkładzie i różnych wartościach średnich

Ryż. 7. Dwa symetryczne rozkłady w kształcie dzwonu o tych samych wartościach średnich i różnym rozrzucie
Istnieje pięć szacunków zmienności danych:
- Zakres,
- zakres międzykwartylowy,
- dyspersja,
- odchylenie standardowe,
- współczynnik zmienności.
zakres
Rozstęp to różnica między największymi i najmniejszymi elementami próbki:
Przesuń = XMax-Xmin
Rozstęp próby zawierającej średnie roczne zwroty 15 funduszy wspólnego inwestowania bardzo wysokiego ryzyka można obliczyć za pomocą uporządkowanej tablicy (zob. wykres 4): rozstęp = 18,5 - (-6,1) = 24,6. Oznacza to, że różnica między najwyższą a najniższą średnią roczną stopą zwrotu dla funduszy bardzo wysokiego ryzyka wynosi 24,6%.
Zakres mierzy ogólny rozrzut danych. Chociaż zakres próbny jest bardzo prostym oszacowaniem całkowitego rozrzutu danych, jego słabością jest to, że nie uwzględnia dokładnie tego, jak dane są rozłożone między elementami minimalnymi i maksymalnymi. Efekt ten jest dobrze widoczny na ryc. 8, która ilustruje próbki mające ten sam zakres. Skala B pokazuje, że jeśli próbka zawiera co najmniej jedną wartość skrajną, zakres próby jest bardzo niedokładnym oszacowaniem rozproszenia danych.

Ryż. 8. Porównanie trzech próbek o tym samym zakresie; trójkąt symbolizuje podparcie wagi, a jego położenie odpowiada średniej wartości próbki
Zakres międzykwartylowy
Rozstęp międzykwartylowy lub średni to różnica między trzecim a pierwszym kwartylem próbki:
Rozstęp międzykwartylowy \u003d Q 3 - Q 1
Ta wartość pozwala oszacować rozrzut pierwiastków na poziomie 50% i nie uwzględniać wpływu pierwiastków ekstremalnych. Rozstęp międzykwartylowy dla próby zawierającej dane o średnich rocznych stopach zwrotu 15 funduszy inwestycyjnych bardzo wysokiego ryzyka można obliczyć na podstawie danych z ryc. 4 (na przykład dla funkcji KWARTYL.PRZEK): Rozstęp międzykwartylowy = 9,8 - (-0,7) = 10,5. Przedział między 9,8 a -0,7 jest często określany jako środkowa połowa.
Należy zauważyć, że wartości Q 1 i Q 3, a co za tym idzie rozstęp międzykwartylowy, nie zależą od obecności wartości odstających, gdyż ich obliczenie nie uwzględnia żadnej wartości, która byłaby mniejsza od Q 1 lub większa od Q 3 . Całkowite cechy ilościowe, takie jak mediana, pierwszy i trzeci kwartyl oraz rozstęp międzykwartylowy, na które nie mają wpływu wartości odstające, nazywane są solidnymi wskaźnikami.
Podczas gdy rozstęp i rozstęp międzykwartylowy zapewniają oszacowanie odpowiednio całkowitego i średniego rozrzutu próby, żadne z tych oszacowań nie uwzględnia dokładnego rozkładu danych. Wariancja i odchylenie standardowe wolny od tego mankamentu. Wskaźniki te pozwalają ocenić stopień fluktuacji danych wokół średniej. Przykładowa wariancja jest przybliżeniem średniej arytmetycznej obliczonej z kwadratów różnic między każdym elementem próbki a średnią z próby. Dla próby X 1 , X 2 , ... X n wariancja próby (oznaczona symbolem S 2 dana jest wzorem:

Ogólnie rzecz biorąc, wariancja próby jest sumą kwadratów różnic między elementami próby a średnią z próby, podzieloną przez wartość równą wielkości próby minus jeden:

gdzie - Średnia arytmetyczna, n- wielkość próbki, X i - ja-ty element próbki X. W programie Excel przed wersją 2007 funkcja =WARIANCJA() była używana do obliczania wariancji próby, od wersji 2010 używana jest funkcja =WARIANCJA.V().
Najbardziej praktycznym i powszechnie akceptowanym oszacowaniem rozproszenia danych jest odchylenie standardowe. Wskaźnik ten jest oznaczony symbolem S i jest równy pierwiastkowi kwadratowemu z wariancji próbki:

W Excelu przed wersją 2007 do obliczania odchylenia standardowego była używana funkcja =STDEV() od wersji 2010 używana jest funkcja =STDEV.B(). Aby obliczyć te funkcje, tablica danych może być nieuporządkowana.
Ani wariancja próbki, ani odchylenie standardowe próbki nie mogą być ujemne. Jedyna sytuacja, w której wskaźniki S 2 i S mogą wynosić zero, to sytuacja, w której wszystkie elementy próby są równe. W tym zupełnie nieprawdopodobnym przypadku rozstęp i rozstęp międzykwartylowy również wynoszą zero.
Dane liczbowe są z natury niestabilne. Każda zmienna może przyjmować wiele różnych wartości. Na przykład różne fundusze inwestycyjne mają różne stopy zwrotu i straty. Ze względu na zmienność danych liczbowych bardzo ważne jest badanie nie tylko oszacowań średniej, które mają charakter sumatywny, ale także oszacowań wariancji, które charakteryzują rozrzut danych.
Wariancja i odchylenie standardowe pozwalają nam oszacować rozrzut danych wokół średniej, innymi słowy określić, ile elementów próby jest mniejszych od średniej, a ile większych. Dyspersja ma kilka cennych właściwości matematycznych. Jednak jego wartość to kwadrat jednostki miary - procent kwadratowy, dolar kwadratowy, cal kwadratowy itp. Dlatego naturalnym oszacowaniem wariancji jest odchylenie standardowe, które wyraża się w zwykłych jednostkach miary - procentach dochodu, dolarach lub calach.
Odchylenie standardowe pozwala oszacować wielkość fluktuacji elementów próbki wokół wartości średniej. W prawie wszystkich sytuacjach większość obserwowanych wartości mieści się w granicach plus lub minus jednego odchylenia standardowego od średniej. Dlatego znając średnią arytmetyczną elementów próby i odchylenie standardowe próby, można określić przedział, do którego należy większość danych.
Odchylenie standardowe stóp zwrotu z 15 funduszy inwestycyjnych bardzo wysokiego ryzyka wynosi 6,6 (wykres 9). Oznacza to, że rentowność większości funduszy odbiega od średniej o nie więcej niż 6,6% (tj. waha się w przedziale od - S= 6,2 – 6,6 = –0,4 do + S= 12,8). W rzeczywistości przedział ten zawiera pięcioletni średni roczny zwrot w wysokości 53,3% (8 z 15) środków.

Ryż. 9. Odchylenie standardowe
Należy zauważyć, że w procesie sumowania różnic do kwadratu pozycje, które są dalej od średniej, zyskują większą wagę niż pozycje, które są bliższe. Ta właściwość jest głównym powodem, dla którego średnia arytmetyczna jest najczęściej używana do oszacowania średniej rozkładu.
Współczynnik zmienności
W przeciwieństwie do poprzednich szacunków rozrzutu, współczynnik zmienności jest oszacowaniem względnym. Jest zawsze mierzony w procentach, a nie w oryginalnych jednostkach danych. Współczynnik zmienności, oznaczony symbolami CV, mierzy rozproszenie danych wokół średniej. Współczynnik zmienności jest równy odchyleniu standardowemu podzielonemu przez średnią arytmetyczną i pomnożonemu przez 100%:

gdzie S- odchylenie standardowe próbki, - próbka średnia.
Współczynnik zmienności pozwala porównać dwie próbki, których elementy są wyrażone w różnych jednostkach miary. Na przykład kierownik usługi dostarczania poczty zamierza unowocześnić flotę samochodów ciężarowych. Podczas ładowania paczek należy wziąć pod uwagę dwa rodzaje ograniczeń: wagę (w funtach) i objętość (w stopach sześciennych) każdej paczki. Załóżmy, że w próbce 200 worków średnia waga wynosi 26,0 funtów, odchylenie standardowe wagi wynosi 3,9 funta, średnia objętość paczki wynosi 8,8 stopy sześciennej, a odchylenie standardowe objętości wynosi 2,2 stopy sześcienne. Jak porównać rozrzut wagi i objętości paczek?
Ponieważ jednostki miary masy i objętości różnią się od siebie, kierownik musi porównać względny rozrzut tych wartości. Współczynnik zmienności wagi wynosi CV W = 3,9 / 26,0 * 100% = 15%, a współczynnik zmienności objętości CV V = 2,2 / 8,8 * 100% = 25%. Zatem względny rozrzut objętości pakietów jest znacznie większy niż względny rozrzut ich wag.
Formularz dystrybucji
Trzecią ważną właściwością próbki jest forma jej dystrybucji. Rozkład ten może być symetryczny lub asymetryczny. Aby opisać kształt rozkładu, konieczne jest obliczenie jego średniej i mediany. Jeśli te dwie miary są takie same, mówi się, że zmienna ma rozkład symetryczny. Jeżeli średnia wartość zmiennej jest większa od mediany, jej rozkład ma dodatnią skośność (rys. 10). Jeśli mediana jest większa niż średnia, rozkład zmiennej jest skośny ujemnie. Dodatnia skośność występuje, gdy średnia wzrasta do niezwykle wysokich wartości. Ujemna skośność występuje, gdy średnia spada do niezwykle małych wartości. Zmienna jest symetrycznie rozłożona, jeśli nie przyjmuje żadnych skrajnych wartości w żadnym kierunku, tak że duże i małe wartości zmiennej znoszą się nawzajem.

Ryż. 10. Trzy rodzaje dystrybucji
Dane przedstawione na skali A mają ujemną skośność. Ta figura pokazuje długi ogon i lewe pochylenie spowodowane niezwykle małymi wartościami. Te skrajnie małe wartości przesuwają wartość średnią w lewo i staje się mniejsza niż mediana. Dane pokazane na skali B rozkładają się symetrycznie. Lewa i prawa połowa rozkładu są ich lustrzanymi odbiciami. Duże i małe wartości równoważą się, a średnia i mediana są sobie równe. Dane pokazane na skali B mają dodatnią skośność. Ta figura pokazuje długi ogon i pochylenie w prawo, spowodowane obecnością niezwykle wysokich wartości. Te zbyt duże wartości przesuwają średnią w prawo i staje się ona większa od mediany.
W programie Excel statystyki opisowe można uzyskać za pomocą dodatku Pakiet analiz. Przejdź przez menu Dane → Analiza danych, w oknie, które zostanie otwarte, wybierz linię Opisowe statystyki i kliknij Ok. W oknie Opisowe statystyki koniecznie zaznacz interwał wejściowy(Rys. 11). Jeśli chcesz zobaczyć statystyki opisowe na tym samym arkuszu co oryginalne dane, zaznacz przycisk radiowy interwał wyjściowy i określ komórkę, w której chcesz umieścić lewy górny róg wyświetlanych statystyk (w naszym przykładzie $C$1). Jeśli chcesz wyprowadzić dane do nowego arkusza lub do nowego skoroszytu, po prostu wybierz odpowiedni przycisk radiowy. Zaznacz pole obok Statystyki końcowe. Opcjonalnie możesz również wybrać Poziom trudności,k-ty najmniejszy ik-ta największa.
Jeśli w depozycie Dane w pobliżu Analiza nie widzisz ikony Analiza danych, musisz najpierw zainstalować dodatek Pakiet analiz(patrz na przykład).

Ryż. 11. Statystyki opisowe pięcioletnich średnich rocznych zwrotów funduszy o bardzo wysokim poziomie ryzyka, obliczonych z wykorzystaniem dodatku Analiza danych programy Excela
Excel oblicza szereg statystyk omówionych powyżej: średnią, medianę, tryb, odchylenie standardowe, wariancję, zakres ( interwał), minimum, maksimum i wielkość próbki ( sprawdzać). Ponadto Excel oblicza dla nas kilka nowych statystyk: błąd standardowy, kurtozę i skośność. Standardowy błąd równa się odchyleniu standardowemu podzielonemu przez pierwiastek kwadratowy wielkości próby. Asymetria charakteryzuje odchylenie od symetrii rozkładu i jest funkcją zależną od sześcianu różnic między elementami próby a wartością średnią. Kurtoza jest miarą względnej koncentracji danych wokół średniej w stosunku do ogonów rozkładu i zależy od różnic między próbką a średnią podniesioną do czwartej potęgi.
Obliczanie statystyk opisowych dla populacji generalnej
Średnia, rozrzut i kształt omówionego powyżej rozkładu są charakterystykami opartymi na próbie. Jeśli jednak zbiór danych zawiera pomiary numeryczne całej populacji, wówczas można obliczyć jego parametry. Parametry te obejmują średnią, wariancję i odchylenie standardowe populacji.
Wartość oczekiwana jest równa sumie wszystkich wartości populacji ogólnej podzielonej przez wielkość populacji ogólnej:

gdzie µ - wartość oczekiwana, Xja- ja-ta obserwacja zmiennej X, N- wielkość populacji ogólnej. W programie Excel do obliczenia wartości oczekiwanej matematycznej używana jest ta sama funkcja, co w przypadku średniej arytmetycznej: =ŚREDNIA().
Wariancja populacji równa sumie kwadratów różnic między elementami populacji ogólnej i maty. oczekiwanie podzielone przez wielkość populacji:

gdzie σ2 jest wariancją populacji ogólnej. Program Excel przed wersją 2007 używa funkcji = WARIANCJA() do obliczania wariancji populacji, począwszy od wersji 2010 = WARIANCJA.G().
odchylenie standardowe populacji jest równe pierwiastkowi kwadratowemu z wariancji populacji:

Program Excel przed wersją 2007 używa =ODCH.STANDARDOWE() do obliczania odchylenia standardowego populacji, począwszy od wersji 2010 =ODCH.STANDARDOWE.Y(). Należy zauważyć, że wzory na wariancję populacji i odchylenie standardowe różnią się od wzorów na wariancję i odchylenie standardowe próby. Podczas obliczania przykładowych statystyk S2 oraz S mianownik ułamka to n - 1 i podczas obliczania parametrów σ2 oraz σ - wielkość populacji ogólnej N.
praktyczna zasada
W większości sytuacji duża część obserwacji koncentruje się wokół mediany, tworząc klaster. W zbiorach danych o skośności dodatniej klaster ten znajduje się na lewo (tj. poniżej) oczekiwań matematycznych, aw zbiorach o skośności ujemnej klaster ten znajduje się na prawo (tj. powyżej) oczekiwań matematycznych. Dane symetryczne mają tę samą średnią i medianę, a obserwacje skupiają się wokół średniej, tworząc rozkład w kształcie dzwonu. Jeśli rozkład nie ma wyraźnej skośności, a dane są skoncentrowane wokół pewnego środka ciężkości, do oszacowania zmienności można zastosować praktyczną regułę, która mówi: jeśli dane mają rozkład w kształcie dzwonu, to około 68% obserwacji jest mniejsza niż jedno odchylenie standardowe od oczekiwań matematycznych, około 95% obserwacji mieści się w granicach dwóch odchyleń standardowych od wartości oczekiwanej, a 99,7% obserwacji mieści się w granicach trzech odchyleń standardowych od wartości oczekiwanej.
Zatem odchylenie standardowe, które jest oszacowaniem średniej fluktuacji wokół oczekiwań matematycznych, pomaga zrozumieć, w jaki sposób rozkładają się obserwacje, i zidentyfikować wartości odstające. Z praktycznej zasady wynika, że dla rozkładów w kształcie dzwonu tylko jedna wartość na dwadzieścia różni się od oczekiwań matematycznych o więcej niż dwa odchylenia standardowe. Dlatego wartości poza przedziałem µ ± 2σ, można uznać za wartości odstające. Ponadto tylko trzy na 1000 obserwacji różnią się od oczekiwań matematycznych o więcej niż trzy odchylenia standardowe. Zatem wartości poza przedziałem µ ± 3σ są prawie zawsze wartościami odstającymi. W przypadku rozkładów, które są silnie skośne lub nie mają kształtu dzwonu, można zastosować praktyczną regułę Biename-Czebyszewa.
Ponad sto lat temu matematycy Bienamay i Czebyszew niezależnie odkryli użyteczną właściwość odchylenia standardowego. Stwierdzili, że dla dowolnego zbioru danych, niezależnie od kształtu rozkładu, odsetek obserwacji leżących w odległości nieprzekraczającej k odchylenia standardowe od oczekiwań matematycznych, nie mniej (1 – 1/ 2)*100%.
Na przykład, jeśli k= 2, reguła Biename-Czebyszewa mówi, że co najmniej (1 - (1/2) 2) x 100% = 75% obserwacji musi mieścić się w przedziale µ ± 2σ. Ta zasada dotyczy każdego k przekraczający jeden. Reguła Biename-Czebyszewa ma bardzo ogólny charakter i obowiązuje dla wszelkiego rodzaju rozkładów. Wskazuje minimalną liczbę obserwacji, od której odległość do matematycznego oczekiwania nie przekracza określonej wartości. Jeśli jednak rozkład ma kształt dzwonu, praktyczna zasada dokładniej szacuje koncentrację danych wokół średniej.
Obliczanie statystyk opisowych dla rozkładu opartego na częstotliwościach
Jeśli oryginalne dane nie są dostępne, rozkład częstotliwości staje się jedynym źródłem informacji. W takich sytuacjach można obliczyć przybliżone wartości wskaźników ilościowych rozkładu, takich jak średnia arytmetyczna, odchylenie standardowe, kwartyle.
Jeśli przykładowe dane zostaną przedstawione w postaci rozkładu częstości, można obliczyć przybliżoną wartość średniej arytmetycznej, zakładając, że wszystkie wartości w obrębie każdej klasy są skoncentrowane w punkcie środkowym klasy:

gdzie - średnia próbki, n- liczba obserwacji lub wielkość próby, Z- ilość klas w rozkładzie częstotliwości, mj- punkt środkowy j-klasa, fj- częstotliwość odpowiadająca j-ta klasa.
Aby obliczyć odchylenie standardowe z rozkładu częstości, zakłada się również, że wszystkie wartości w obrębie każdej klasy są skoncentrowane w punkcie środkowym klasy.

Aby zrozumieć, w jaki sposób kwartyle szeregu są wyznaczane na podstawie częstości, rozważmy obliczenie dolnego kwartyla na podstawie danych za 2013 r. dotyczących rozkładu ludności rosyjskiej według średniego dochodu pieniężnego na mieszkańca (ryc. 12).

Ryż. 12. Udział ludności Rosji o dochodzie pieniężnym na mieszkańca średnio miesięcznie, ruble
Aby obliczyć pierwszy kwartyl szeregu zmienności interwału, można skorzystać ze wzoru:

gdzie Q1 to wartość pierwszego kwartyla, xQ1 to dolna granica przedziału zawierającego pierwszy kwartyl (przedział wyznacza częstość skumulowana, pierwsza przekracza 25%); i jest wartością przedziału; Σf jest sumą częstotliwości całej próbki; prawdopodobnie zawsze równa 100%; SQ1–1 to skumulowana częstość przedziału poprzedzającego przedział zawierający dolny kwartyl; fQ1 to częstotliwość przedziału zawierającego dolny kwartyl. Wzór na trzeci kwartyl różni się tym, że we wszystkich miejscach zamiast Q1 trzeba użyć Q3 i zastąpić ¾ zamiast ¼.
W naszym przykładzie (ryc. 12) dolny kwartyl mieści się w przedziale 7000,1 - 10 000, którego skumulowana częstość wynosi 26,4%. Dolna granica tego przedziału wynosi 7000 rubli, wartość przedziału wynosi 3000 rubli, skumulowana częstotliwość przedziału poprzedzającego przedział zawierający dolny kwartyl wynosi 13,4%, częstotliwość przedziału zawierającego dolny kwartyl wynosi 13,0%. Zatem: Q1 \u003d 7000 + 3000 * (¼ * 100 - 13,4) / 13 \u003d 9677 rubli.
Pułapki związane ze statystykami opisowymi
W tej notatce przyjrzeliśmy się, jak opisać zbiór danych za pomocą różnych statystyk, które szacują jego średnią, rozproszenie i rozkład. Kolejnym krokiem jest analiza i interpretacja danych. Do tej pory badaliśmy obiektywne właściwości danych, a teraz przechodzimy do ich subiektywnej interpretacji. Na badacza czyhają dwa błędy: niewłaściwie wybrany przedmiot analizy i niewłaściwa interpretacja wyników.
Analiza wyników 15 funduszy inwestycyjnych bardzo wysokiego ryzyka jest dość obiektywna. Doprowadził do całkowicie obiektywnych wniosków: wszystkie fundusze inwestycyjne mają różne zwroty, rozpiętość zwrotów funduszy waha się od -6,1 do 18,5, a średnia stopa zwrotu to 6,08. Obiektywizm analizy danych zapewnia właściwy dobór łącznych wskaźników ilościowych rozkładu. Rozważono kilka metod szacowania średniej i rozrzutu danych oraz wskazano ich wady i zalety. Jak wybrać odpowiednie statystyki, które zapewnią obiektywną i bezstronną analizę? Jeśli rozkład danych jest lekko skośny, czy należy wybrać medianę zamiast średniej arytmetycznej? Który wskaźnik dokładniej charakteryzuje rozrzut danych: odchylenie standardowe czy zakres? Czy należy wskazać dodatnią skośność rozkładu?
Z drugiej strony interpretacja danych jest procesem subiektywnym. Różni ludzie dochodzą do różnych wniosków, interpretując te same wyniki. Każdy ma swój punkt widzenia. Ktoś uważa łączne średnie roczne zwroty 15 funduszy o bardzo wysokim poziomie ryzyka za dobre i jest całkiem zadowolony z otrzymanych dochodów. Inni mogą pomyśleć, że te fundusze mają zbyt niskie zwroty. Subiektywność powinna więc być rekompensowana szczerością, neutralnością i jasnością wniosków.
Zagadnienia etyczne
Analiza danych jest nierozerwalnie związana z kwestiami etycznymi. Należy krytycznie odnosić się do informacji rozpowszechnianych przez prasę, radio, telewizję i Internet. Z czasem nauczysz się sceptycznie podchodzić nie tylko do wyników, ale także do celów, przedmiotu i obiektywności badań. Słynny brytyjski polityk Benjamin Disraeli ujął to najlepiej: „Istnieją trzy rodzaje kłamstw: kłamstwa, cholerne kłamstwa i statystyki”.
Jak zauważono w notatce, kwestie etyczne pojawiają się przy wyborze wyników, które powinny zostać zaprezentowane w raporcie. Należy opublikować zarówno pozytywne, jak i negatywne wyniki. Ponadto przy sporządzaniu raportu lub raportu pisemnego wyniki muszą być przedstawione rzetelnie, neutralnie i obiektywnie. Rozróżnij złe i nieuczciwe prezentacje. Aby to zrobić, konieczne jest ustalenie, jakie były intencje mówcy. Czasami mówca pomija ważne informacje z niewiedzy, a czasami celowo (na przykład, jeśli używa średniej arytmetycznej do oszacowania średniej z wyraźnie wypaczonych danych, aby uzyskać pożądany wynik). Nieuczciwe jest również ukrywanie wyników, które nie odpowiadają punktowi widzenia badacza.
Wykorzystano materiały z książki Levin i wsp. Statystyki dla menedżerów. - M.: Williams, 2004. - s. 178–209
Funkcja KWARTYL została zachowana w celu dostosowania do wcześniejszych wersji programu Excel
Przede wszystkim w ew. W praktyce trzeba posługiwać się średnią arytmetyczną, którą można obliczyć jako prostą i ważoną średnią arytmetyczną.
Średnia arytmetyczna (CA)-n najpowszechniejszy typ medium. Stosuje się go w przypadkach, gdy objętość atrybutu zmiennej dla całej populacji jest sumą wartości atrybutów poszczególnych jej jednostek. Zjawiska społeczne charakteryzują się addytywnością (sumowaniem) wielkości zmiennego atrybutu, co określa zakres SA i wyjaśnia jego rozpowszechnienie jako wskaźnik uogólniający, na przykład: ogólny fundusz wynagrodzeń to suma wynagrodzeń wszystkich pracowników.
Aby obliczyć SA, musisz podzielić sumę wszystkich wartości cech przez ich liczbę. SA jest używany w 2 formach.
Rozważ najpierw prostą średnią arytmetyczną.
1-CA proste (początkowa, definiująca postać) jest równa prostej sumie poszczególnych wartości uśrednionej cechy, podzielonej przez całkowitą liczbę tych wartości (stosowane, gdy występują niezgrupowane wartości indeksowe cechy):
Wykonane obliczenia można podsumować następującym wzorem:
 (1)
(1)
gdzie  - średnia wartość atrybutu zmiennej, czyli prosta średnia arytmetyczna;
- średnia wartość atrybutu zmiennej, czyli prosta średnia arytmetyczna;
 oznacza sumowanie, czyli dodawanie poszczególnych cech;
oznacza sumowanie, czyli dodawanie poszczególnych cech;
x- poszczególne wartości atrybutu zmiennej, które nazywane są wariantami;
n - liczba jednostek ludności
Przykład 1, trzeba znaleźć przeciętną produkcję jednego robotnika (ślusarza), jeśli wiadomo, ile części wyprodukował każdy z 15 robotników, tj. podany numer ind. wartości cech, szt.: 21; 20; 20; dziewiętnaście; 21; dziewiętnaście; osiemnaście; 22; dziewiętnaście; 20; 21; 20; osiemnaście; dziewiętnaście; 20.
SA prosty oblicza się według wzoru (1), szt.:
Przykład2. Obliczmy SA na podstawie danych warunkowych dla 20 sklepów wchodzących w skład firmy handlowej (Tabela 1). Tabela 1
Rozmieszczenie sklepów firmy handlowej „Vesna” według powierzchni handlowej, mkw. M
|
numer sklepu |
numer sklepu | ||
Aby obliczyć średnią powierzchnię sklepu ( 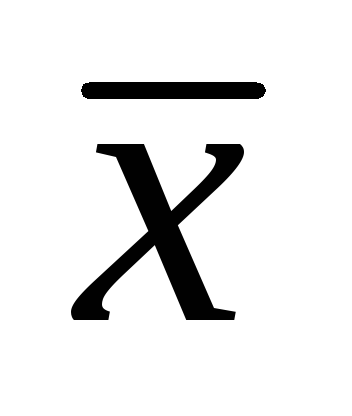 ) należy zsumować powierzchnie wszystkich sklepów i podzielić wynik przez liczbę sklepów:
) należy zsumować powierzchnie wszystkich sklepów i podzielić wynik przez liczbę sklepów:

Tym samym średnia powierzchnia sklepów dla tej grupy przedsiębiorstw handlowych wynosi 71 mkw.
Dlatego, aby wyznaczenie SA było proste, należy podzielić sumę wszystkich wartości danego atrybutu przez liczbę jednostek posiadających ten atrybut.
2
gdzie f 1
,
f 2
,
… ,f n
–
waga (częstotliwość powtarzania się tych samych cech); jest sumą iloczynów wielkości cech i ich częstości; to całkowita liczba jednostek populacji.![]() (2)
(2)
Gdzie X- opcje;
f- częstotliwość (waga).
Ważona SA to iloraz sumy iloczynów wariantów i odpowiadających im częstości przez sumę wszystkich częstości. Częstotliwości ( f) występujące w formule SA są zwykle nazywane waga, w wyniku czego SA obliczony z uwzględnieniem wag nazywany jest ważonym SA.
Zilustrujemy technikę obliczania ważonego SA za pomocą rozważanego powyżej przykładu 1. W tym celu grupujemy początkowe dane i umieszczamy je w tabeli.
Średnią zgrupowanych danych wyznacza się w następujący sposób: najpierw mnoży się warianty przez częstości, następnie dodaje się iloczyny i otrzymaną sumę dzieli się przez sumę częstości.
Zgodnie ze wzorem (2) ważony SA wynosi szt.: ![]()

P

Rozkład sklepów Vesna według powierzchni handlowej mkw. m
Zatem wynik jest taki sam. Będzie to jednak już średnia arytmetyczna ważona.
W poprzednim przykładzie obliczyliśmy średnią arytmetyczną, pod warunkiem, że znane są bezwzględne częstotliwości (liczba sklepów). Jednak w niektórych przypadkach nie ma bezwzględnych częstotliwości, ale znane są częstotliwości względne lub, jak się je powszechnie nazywa, częstotliwości, które pokazują proporcję lub udział frekwencji w całej populacji.
Przy obliczaniu użycia ważonego SA częstotliwości pozwala uprościć obliczenia, gdy częstotliwość jest wyrażona dużymi, wielocyfrowymi liczbami. Obliczenia wykonuje się w ten sam sposób, jednak ponieważ wartość średnia jest zwiększana 100-krotnie, wynik należy podzielić przez 100.
Wtedy wzór na arytmetyczną średnią ważoną będzie wyglądał następująco:
gdzie d- częstotliwość, tj. udział każdej częstotliwości w całkowitej sumie wszystkich częstotliwości.
(3)W naszym przykładzie 2 najpierw określamy udział sklepów według grup w ogólnej liczbie sklepów firmy „Wiosna”. Tak więc dla pierwszej grupy ciężar właściwy odpowiada 10%  . Otrzymujemy następujące dane Tabela 3
. Otrzymujemy następujące dane Tabela 3
Wartości średnie odnoszą się do uogólniających wskaźników statystycznych, które dają zbiorczą (ostateczną) charakterystykę masowych zjawisk społecznych, ponieważ są one budowane na podstawie dużej liczby indywidualnych wartości o różnym atrybucie. Aby wyjaśnić istotę wartości średniej, należy wziąć pod uwagę cechy kształtowania się wartości znaków tych zjawisk, zgodnie z którymi obliczana jest wartość średnia.
Wiadomo, że jednostki każdego zjawiska masowego mają wiele cech. Niezależnie od tego, który z tych znaków przyjmiemy, jego wartości dla poszczególnych jednostek będą różne, zmieniają się one lub, jak mówią statystyki, różnią się w zależności od jednostki. I tak np. o wynagrodzeniu pracownika decydują jego kwalifikacje, charakter wykonywanej pracy, staż pracy i szereg innych czynników, a zatem waha się w bardzo szerokim zakresie. Skumulowany wpływ wszystkich czynników determinuje wysokość zarobków każdego pracownika, jednak możemy mówić o przeciętnych miesięcznych wynagrodzeniach pracowników w różnych sektorach gospodarki. Operujemy tu typową, charakterystyczną wartością atrybutu zmiennej, odniesionego do jednostki dużej populacji.
Średnia to odzwierciedla ogólny, co jest charakterystyczne dla wszystkich jednostek badanej populacji. Równocześnie równoważy wpływ wszystkich czynników oddziałujących na wielkość atrybutu poszczególnych jednostek populacji, niejako wzajemnie się znosząc. O poziomie (lub wielkości) każdego zjawiska społecznego decyduje działanie dwóch grup czynników. Niektóre z nich mają charakter ogólny i główny, stale działający, ściśle związany z naturą badanego zjawiska lub procesu i go tworzą typowy dla wszystkich jednostek badanej populacji, co znajduje odzwierciedlenie w wartości średniej. Inni są indywidualny, ich działanie jest mniej wyraźne i jest epizodyczne, losowe. Działają w przeciwnym kierunku, powodują różnice między cechami ilościowymi poszczególnych jednostek populacji, dążąc do zmiany stałej wartości badanych cech. Działanie poszczególnych znaków wygasa w wartości średniej. W skumulowanym wpływie czynników typowych i indywidualnych, który jest równoważony i wzajemnie znosi się w uogólniających cechach, fundamentalne prawo wielkich liczb.
W sumie poszczególne wartości znaków łączą się we wspólną masę i niejako rozpuszczają się. Stąd i Średnia wartość działa jako „bezosobowy”, który może odbiegać od indywidualnych wartości cech, nie pokrywając się ilościowo z żadną z nich. Średnia wartość odzwierciedla ogólną, charakterystyczną i typową dla całej populacji ze względu na wzajemne znoszenie się w niej przypadkowych, nietypowych różnic między znakami poszczególnych jej jednostek, ponieważ jej wartość jest określona niejako przez wspólną wypadkową wszystkich powoduje.
Aby jednak wartość średnia odzwierciedlała najbardziej typową wartość cechy, nie należy jej wyznaczać dla żadnych populacji, a jedynie dla populacji składających się z jednostek jakościowo jednorodnych. Wymóg ten jest głównym warunkiem naukowego zastosowania średnich i implikuje ścisły związek między metodą średnich a metodą grupowania w analizie zjawisk społeczno-gospodarczych. Wartość średnia jest zatem wskaźnikiem uogólniającym, charakteryzującym typowy poziom cechy zmiennej na jednostkę jednorodnej populacji w określonych warunkach miejsca i czasu.
Określając zatem istotę wartości średnich, należy podkreślić, że prawidłowe obliczenie dowolnej wartości średniej oznacza spełnienie następujących wymagań:
- jakościowa jednorodność populacji, na podstawie której obliczana jest wartość średnia. Oznacza to, że obliczenia wartości średnich powinny opierać się na metodzie grupowania, która zapewnia selekcję zjawisk jednorodnych, tego samego typu;
- wykluczenie wpływu na obliczenie średniej wartości przypadkowych, czysto indywidualnych przyczyn i czynników. Osiąga się to, gdy obliczenie średniej opiera się na wystarczająco masywnym materiale, w którym przejawia się działanie prawa wielkich liczb, a wszystkie wypadki wzajemnie się znoszą;
- przy obliczaniu wartości średniej ważne jest ustalenie celu jej obliczenia oraz tzw definiowanie wskaźnika-tel(właściwość), do której powinien być zorientowany.
Wskaźnik określający może działać jako suma wartości uśrednionego atrybutu, suma jego odwrotności, iloczyn jego wartości itp. Związek między wskaźnikiem definiującym a wartością średnią wyraża się następująco: jeśli wszystkie wartości uśrednionego atrybutu zostaną zastąpione wartością średnią, wówczas ich suma lub iloczyn w tym przypadku nie zmieni wskaźnika definiującego. Na podstawie tego połączenia wskaźnika determinującego z wartością średnią budowany jest wstępny wskaźnik ilościowy do bezpośredniego obliczenia wartości średniej. Zdolność średnich do zachowania właściwości populacji statystycznych nazywa się definiowanie właściwości.
Średnia wartość obliczona dla całej populacji to tzw Średnia ogólna;średnie wartości obliczone dla każdej grupy - średnie grupowe.Średnia ogólna odzwierciedla ogólne cechy badanego zjawiska, średnia grupowa daje opis zjawiska, które rozwija się w specyficznych warunkach tej grupy.
Metody obliczania mogą być różne, dlatego w statystyce wyróżnia się kilka rodzajów średnich, z których głównymi są średnia arytmetyczna, średnia harmoniczna i średnia geometryczna.
W analizie ekonomicznej posługiwanie się średnimi jest głównym narzędziem oceny wyników postępu naukowo-technicznego, mierników społecznych oraz poszukiwania rezerw dla rozwoju gospodarczego. Jednocześnie należy pamiętać, że nadmierne skupianie się na średnich może prowadzić do stronniczych wniosków przy prowadzeniu analiz ekonomicznych i statystycznych. Wynika to z faktu, że wartości średnie, będące wskaźnikami uogólniającymi, niwelują i ignorują te różnice w charakterystyce ilościowej poszczególnych jednostek populacji, które rzeczywiście istnieją i mogą stanowić niezależny przedmiot zainteresowania.
Rodzaje średnich
W statystyce stosuje się różne rodzaje średnich, które dzielą się na dwie duże klasy:
- średnie mocy (średnia harmoniczna, średnia geometryczna, średnia arytmetyczna, średnia kwadratowa, średnia sześcienna);
- średnie strukturalne (tryb, mediana).
Liczyć moc oznacza należy wykorzystać wszystkie dostępne wartości charakterystyczne. Moda oraz mediana są określane tylko przez strukturę rozkładu, dlatego nazywane są średnimi strukturalnymi, pozycyjnymi. Mediana i mod są często używane jako średnia charakterystyka w populacjach, w których obliczenie średniej wykładniczej jest niemożliwe lub niepraktyczne.
Najpopularniejszym typem średniej jest średnia arytmetyczna. Pod Średnia arytmetyczna rozumiana jest jako taka wartość cechy, jaką miałaby każda jednostka populacji, gdyby suma wszystkich wartości cechy była równomiernie rozłożona na wszystkie jednostki populacji. Obliczenie tej wartości sprowadza się do zsumowania wszystkich wartości atrybutu zmiennej i podzielenia otrzymanej kwoty przez całkowitą liczbę jednostek populacji. Na przykład pięciu pracowników zrealizowało zamówienie na produkcję części, podczas gdy pierwszy wyprodukował 5 części, drugi 7, trzeci 4, czwarty 10, piąty 12. Ponieważ w danych początkowych wartość każdego opcja wystąpiła tylko raz, aby określić średnią wydajność jednego pracownika należy zastosować prosty wzór na średnią arytmetyczną:
tj. w naszym przykładzie średnia produkcja jednego pracownika jest równa

Wraz z prostą średnią arytmetyczną uczą się ważona średnia arytmetyczna. Dla przykładu obliczmy średni wiek uczniów w grupie 20 osób, których wiek waha się od 18 do 22 lat, gdzie xi- warianty cechy uśrednionej, fi- częstotliwość, która pokazuje, ile razy to występuje i-ty wartość w agregacie (Tabela 5.1).
Tabela 5.1
Średni wiek uczniów
Stosując wzór na ważoną średnią arytmetyczną, otrzymujemy:

Istnieje pewna zasada wyboru ważonej średniej arytmetycznej: jeśli istnieje seria danych dotyczących dwóch wskaźników, z których jeden należy obliczyć
średnia wartość, a jednocześnie wartości liczbowe mianownika jego wzoru logicznego są znane, a wartości licznika są nieznane, ale można je znaleźć jako iloczyn tych wskaźników, wówczas wartość średnią należy obliczyć za pomocą wzoru na średnią ważoną arytmetyczną.
W niektórych przypadkach charakter początkowych danych statystycznych jest taki, że obliczenie średniej arytmetycznej traci sens, a jedynym uogólniającym wskaźnikiem może być tylko inny rodzaj wartości średniej - średnia harmoniczna. Obecnie właściwości obliczeniowe średniej arytmetycznej straciły na znaczeniu w obliczaniu uogólniających wskaźników statystycznych z powodu powszechnego wprowadzania komputerów elektronicznych. Średnia wartość harmoniczna, która jest również prosta i ważona, nabrała wielkiego znaczenia praktycznego. Jeżeli znane są wartości liczbowe licznika formuły logicznej, a wartości mianownika są nieznane, ale można je znaleźć jako prywatny podział jednego wskaźnika przez inny, wówczas wartość średnią oblicza się na podstawie ważonej wzór na średnią harmoniczną.
Dla przykładu niech będzie wiadomo, że samochód przejechał pierwsze 210 km z prędkością 70 km/h, a pozostałe 150 km z prędkością 75 km/h. Niemożliwe jest wyznaczenie średniej prędkości samochodu na całej trasie 360 km za pomocą wzoru na średnią arytmetyczną. Ponieważ opcjami są prędkości w poszczególnych sekcjach xj= 70 km/h i x2= 75 km/h, a odpowiednimi odcinkami drogi są wagi (fi), to iloczyny opcji według wag nie będą miały ani fizycznego, ani ekonomicznego znaczenia. W tym przypadku sensowne jest podzielenie odcinków ścieżki na odpowiadające im prędkości (opcje xi), czyli czas poświęcony na pokonanie poszczególnych odcinków ścieżki (fi / xi). Jeżeli odcinki ścieżki oznaczamy przez fi, to cała ścieżka jest wyrażona jako Σfi, a czas spędzony na całej ścieżce jako Σ fi / xi , Następnie średnią prędkość można znaleźć jako iloraz całkowitej odległości podzielonej przez całkowity czas spędzony:

W naszym przykładzie otrzymujemy:

Jeśli przy użyciu średniej wagi harmonicznej wszystkich opcji (f) są równe, to zamiast ważonej można użyć prosta (nieważona) średnia harmoniczna:

gdzie xi - poszczególne opcje; n- liczba wariantów uśrednionej cechy. W przykładzie z prędkością można by zastosować prostą średnią harmoniczną, gdyby odcinki drogi przebytej z różnymi prędkościami były równe.
Każdą wartość średnią należy obliczyć tak, aby przy zamianie każdego wariantu uśrednionej cechy nie zmieniła się wartość jakiegoś końcowego, uogólniającego wskaźnika, który jest powiązany ze wskaźnikiem uśrednionym. Tak więc, zastępując rzeczywiste prędkości na poszczególnych odcinkach ścieżki ich wartością średnią (średnią prędkością), całkowity dystans nie powinien się zmieniać.
Postać (formuła) wartości średniej jest zdeterminowana charakterem (mechanizmem) relacji tego wskaźnika końcowego z uśrednionym, a więc wskaźnikiem końcowym, którego wartość nie powinna ulec zmianie przy zastąpieniu opcji ich wartością średnią , nazywa się wskaźnik definiujący. Aby wyprowadzić średnią formułę, musisz ułożyć i rozwiązać równanie, korzystając z relacji uśrednionego wskaźnika z determinującym. Równanie to jest konstruowane poprzez zastąpienie wariantów uśrednionej cechy (wskaźnika) ich wartością średnią.
Oprócz średniej arytmetycznej i harmonicznej w statystyce stosuje się również inne rodzaje (formy) średniej. Wszystkie to przypadki specjalne. średnia stopnia. Jeśli obliczymy wszystkie rodzaje średnich potęgowych dla tych samych danych, to wartości
będą takie same, tutaj obowiązuje zasada majoratśredni. Wraz ze wzrostem wykładnika średniej rośnie również sama średnia. Najczęściej stosowane w badaniach praktycznych wzory do obliczania różnych typów średnich wartości mocy przedstawiono w tabeli. 5.2.
Tabela 5.2

Średnia geometryczna jest stosowana, jeśli jest dostępna. n czynniki wzrostu, natomiast poszczególne wartości cechy są z reguły względnymi wartościami dynamiki, zbudowanymi w postaci wartości łańcuchowych, jako stosunek do poprzedniego poziomu każdego poziomu w szeregach dynamiki. Średnia charakteryzuje zatem średnią stopę wzrostu. średnia geometryczna prosta obliczone według wzoru

Formuła średnia geometryczna ważona ma następującą postać:

Powyższe wzory są identyczne, ale jeden stosuje się przy bieżących współczynnikach lub stopach wzrostu, a drugi przy wartościach bezwzględnych poziomów szeregu.
średnia kwadratowa jest używany przy obliczaniu z wartościami funkcji kwadratowych, służy do pomiaru stopnia fluktuacji poszczególnych wartości atrybutu wokół średniej arytmetycznej w szeregach dystrybucyjnych i jest obliczany według wzoru

Średni kwadrat ważony oblicza się według innego wzoru:

Średni sześcienny jest używany podczas obliczania z wartościami funkcji sześciennych i jest obliczany według wzoru

średnia ważona sześcienna:

Wszystkie powyższe średnie wartości można przedstawić jako ogólny wzór:

gdzie jest wartość średnia; - wartość indywidualna; n- liczba jednostek badanej populacji; k- wykładnik, który określa rodzaj średniej.
Przy korzystaniu z tych samych danych źródłowych tym więcej k w ogólnym wzorze potęgi średniej, im większa wartość średnia. Wynika z tego, że istnieje regularna zależność pomiędzy wartościami środków władzy:
Opisane powyżej średnie wartości dają ogólne wyobrażenie o badanej populacji iz tego punktu widzenia ich znaczenie teoretyczne, stosowane i poznawcze jest niepodważalne. Ale zdarza się, że wartość średniej nie pokrywa się z żadną z realnie istniejących opcji, dlatego oprócz rozważanych średnich, w analizie statystycznej wskazane jest wykorzystanie wartości konkretnych opcji, które zajmują dość określona pozycja w uporządkowanym (uszeregowanym) szeregu wartości atrybutów. Wśród tych ilości najczęściej stosowane są strukturalny, lub opisowy, średni- tryb (Mo) i mediana (Me).
Moda- wartość cechy, która najczęściej występuje w tej populacji. W odniesieniu do szeregów wariacyjnych modą jest najczęściej występująca wartość szeregu rankingowego, czyli wariant o największej częstości. Modę można wykorzystać do określenia najczęściej odwiedzanych sklepów, najczęstszej ceny dowolnego produktu. Pokazuje wielkość cechy charakterystycznej dla znacznej części populacji i jest określona wzorem

gdzie x0 jest dolną granicą przedziału; h- wartość interwału; fm- częstotliwość interwałów; fm_ 1 - częstotliwość poprzedniego interwału; fm+ 1 - częstotliwość następnego interwału.
mediana nazywa się wariant znajdujący się na środku rzędu rankingowego. Mediana dzieli szereg na dwie równe części w taki sposób, że po obu jego stronach znajduje się taka sama liczba jednostek populacji. Jednocześnie w jednej połowie jednostek populacji wartość atrybutu zmiennej jest mniejsza od mediany, w drugiej połowie jest od niej większa. Mediana jest używana podczas badania elementu, którego wartość jest większa lub równa lub jednocześnie mniejsza lub równa połowie elementów szeregu dystrybucyjnego. Mediana daje ogólne wyobrażenie o tym, gdzie koncentrują się wartości cechy, innymi słowy, gdzie jest ich centrum.
Opisowy charakter mediany przejawia się w tym, że charakteryzuje ona ilościową granicę wartości atrybutu zmiennego, które posiada połowa jednostek populacji. Problem znalezienia mediany dla dyskretnego szeregu wariacyjnego jest rozwiązany w prosty sposób. Jeżeli wszystkim jednostkom serii nadano numery seryjne, to numer seryjny wariantu mediany definiuje się jako (n + 1) / 2 z nieparzystą liczbą członków n. Jeśli liczba członków serii jest liczbą parzystą, wtedy mediana będzie średnią z dwóch wariantów z numerami seryjnymi n/ 2 i n / 2 + 1.
Podczas wyznaczania mediany w szeregach zmienności interwałów, najpierw określa się przedział, w którym się ona znajduje (przedział mediany). Przedział ten charakteryzuje się tym, że jego skumulowana suma częstości jest równa lub przekracza połowę sumy wszystkich częstości szeregu. Obliczenie mediany szeregu zmian interwałowych przeprowadza się według wzoru

gdzie X0- dolna granica przedziału; h- wartość interwału; fm- częstotliwość interwałów; f- liczba członków serii;
∫m-1 - suma skumulowanych wyrazów szeregu poprzedzającego ten.
Wraz z medianą dla pełniejszego scharakteryzowania struktury badanej populacji wykorzystuje się inne wartości opcji, które zajmują dość określoną pozycję w szeregach rankingowych. Obejmują one kwartyle oraz decyle. Kwartyle dzielą szereg przez sumę częstości na 4 równe części, a decyle - na 10 równych części. Istnieją trzy kwartyle i dziewięć decyli.
Mediana i tryb, w przeciwieństwie do średniej arytmetycznej, nie niwelują różnic indywidualnych w wartościach atrybutu zmiennej, a zatem są dodatkowymi i bardzo ważnymi cechami populacji statystycznej. W praktyce często stosuje się je zamiast średniej lub razem z nią. Szczególnie celowe jest obliczenie mediany i trybu w tych przypadkach, gdy badana populacja zawiera pewną liczbę jednostek o bardzo dużej lub bardzo małej wartości atrybutu zmiennej. Te mało charakterystyczne dla populacji wartości opcji, wpływając jednocześnie na wartość średniej arytmetycznej, nie wpływają na wartości mediany i trybu, co czyni te ostatnie bardzo cennymi wskaźnikami do analiz ekonomicznych i statystycznych .
Wskaźniki zmienności
Celem badania statystycznego jest identyfikacja głównych właściwości i wzorców badanej populacji statystycznej. W procesie zbiorczego przetwarzania statystycznych danych obserwacyjnych budujemy linie dystrybucyjne. Istnieją dwa rodzaje szeregów dystrybucyjnych – atrybutywny i wariacyjny, w zależności od tego, czy atrybut przyjęty za podstawę grupowania jest jakościowy czy ilościowy.
wariacyjne zwane szeregami dystrybucyjnymi zbudowanymi na podstawie ilościowej. Wartości cech ilościowych dla poszczególnych jednostek populacji nie są stałe, mniej więcej różnią się od siebie. Ta różnica w wartości cechy nazywa się wariacje. Oddzielne wartości liczbowe cechy występującej w badanej populacji to tzw opcje wartości. Występowanie zróżnicowania w poszczególnych jednostkach populacji wynika z wpływu dużej liczby czynników na kształtowanie się poziomu cechy. Badanie charakteru i stopnia zróżnicowania cech w poszczególnych jednostkach populacji jest najważniejszym zagadnieniem każdego opracowania statystycznego. Wskaźniki zmienności służą do opisu miary zmienności cechy.
Innym ważnym zadaniem badań statystycznych jest określenie roli poszczególnych czynników lub ich grup w zmienności pewnych cech populacji. Aby rozwiązać taki problem w statystyce, stosuje się specjalne metody badania zmienności, oparte na wykorzystaniu systemu wskaźników mierzących zmienność. W praktyce badacz ma do czynienia z wystarczająco dużą liczbą opcji wartości atrybutu, co nie daje wyobrażenia o rozkładzie jednostek według wartości atrybutu w agregacie. Aby to zrobić, wszystkie warianty wartości atrybutów są ułożone w porządku rosnącym lub malejącym. Proces ten nazywa się ranking wierszy. Serie rankingowe od razu dają ogólne wyobrażenie o wartościach, jakie cecha przyjmuje w agregacie.
Niewystarczalność wartości średniej do wyczerpującej charakterystyki populacji powoduje konieczność uzupełnienia wartości średnich o wskaźniki, które umożliwiają ocenę typowości tych średnich poprzez pomiar fluktuacji (zmienności) badanej cechy. Wykorzystanie tych wskaźników zmienności pozwala uczynić analizę statystyczną pełniejszą i sensowniejszą, a tym samym lepiej zrozumieć istotę badanych zjawisk społecznych.
Najprostszymi oznakami zmienności są minimum oraz maksimum - jest to najmniejsza i największa wartość cechy w populacji. Liczba powtórzeń poszczególnych wariantów wartości cech jest tzw częstotliwość powtarzania. Oznaczmy częstotliwość powtarzania się wartości cechy fi, suma częstości równa objętości badanej populacji wyniesie:
gdzie k- liczba wariantów wartości atrybutów. Wygodne jest zastąpienie częstotliwości częstotliwościami - wi Częstotliwość- wskaźnik częstości względnej - może być wyrażony w ułamkach jednostki lub procentach i pozwala na porównanie szeregów wariacyjnych z różną liczbą obserwacji. Formalnie mamy:

Aby zmierzyć zmienność cechy, stosuje się różne wskaźniki bezwzględne i względne. Bezwzględne wskaźniki zmienności obejmują średnie odchylenie liniowe, zakres zmienności, wariancję, odchylenie standardowe.
Zmienność rozpiętości(R) to różnica między maksymalną a minimalną wartością cechy w badanej populacji: R= Xmaks - Xmin. Ten wskaźnik daje tylko najbardziej ogólne wyobrażenie o fluktuacji badanej cechy, ponieważ pokazuje różnicę tylko między wartościami granicznymi wariantów. Jest on zupełnie niezwiązany z częstościami w szeregu wariacyjnym, czyli z charakterem rozkładu, a jego zależność może nadać mu niestabilny, losowy charakter dopiero od skrajnych wartości atrybutu. Zakres zmienności nie dostarcza informacji o cechach badanych populacji i nie pozwala ocenić stopnia typowości uzyskanych wartości średnich. Zakres tego wskaźnika jest ograniczony do dość jednorodnych populacji, a dokładniej charakteryzuje zmienność cechy, wskaźnik oparty na uwzględnieniu zmienności wszystkich wartości cechy.
Aby scharakteryzować zmienność cechy, konieczne jest uogólnienie odchyleń wszystkich wartości od dowolnej wartości typowej dla badanej populacji. Takie wskaźniki
wariancje, takie jak średnie odchylenie liniowe, wariancja i odchylenie standardowe, opierają się na uwzględnieniu odchyleń wartości atrybutu poszczególnych jednostek populacji od średniej arytmetycznej.
Średnie odchylenie liniowe jest średnią arytmetyczną wartości bezwzględnych odchyleń poszczególnych opcji od ich średniej arytmetycznej:

Wartość bezwzględna (moduł) odchylenia wariantu od średniej arytmetycznej; f- częstotliwość.
Pierwsza formuła jest stosowana, jeśli każda z opcji występuje w agregacie tylko raz, a druga - szeregowo z nierównymi częstościami.
Istnieje inny sposób uśrednienia odchyleń opcji od średniej arytmetycznej. Metoda ta, bardzo powszechna w statystyce, sprowadza się do obliczenia kwadratów odchyleń opcji od wartości średniej, a następnie ich uśrednienia. W tym przypadku otrzymujemy nowy wskaźnik zmienności - wariancję.
Dyspersja(σ 2) - średnia kwadratów odchyleń wariantów wartości cechy od ich średniej wartości:

Drugi wzór jest używany, jeśli warianty mają własne wagi (lub częstotliwości serii wariacji).
W analizie ekonomicznej i statystycznej przyjęło się oceniać zmienność cechy najczęściej za pomocą odchylenia standardowego. Odchylenie standardowe(σ) jest pierwiastkiem kwadratowym z wariancji:

Średnie odchylenia liniowe i średniokwadratowe pokazują, jak bardzo wartość atrybutu zmienia się średnio dla jednostek badanej populacji i są wyrażone w tych samych jednostkach, co warianty.
W praktyce statystycznej często zachodzi konieczność porównania zmienności różnych cech. Na przykład bardzo interesujące jest porównanie zmienności wieku personelu i jego kwalifikacji, stażu pracy i płac itp. Do takich porównań wskaźniki bezwzględnej zmienności znaków - średnie odchylenie liniowe i standardowe - nie są odpowiednie . W rzeczywistości nie można porównywać fluktuacji stażu pracy wyrażonej w latach z fluktuacją płacy wyrażonej w rublach i kopiejkach.
Porównując zmienność różnych cech w agregacie, wygodnie jest użyć względnych wskaźników zmienności. Wskaźniki te są obliczane jako stosunek wskaźników bezwzględnych do średniej arytmetycznej (lub mediany). Wykorzystując jako bezwzględny wskaźnik zmienności zakres zmienności, średnie odchylenie liniowe, odchylenie standardowe, otrzymuje się względne wskaźniki zmienności:

Najczęściej stosowany wskaźnik zmienności względnej, charakteryzujący jednorodność populacji. Zbiór uważa się za jednorodny, jeżeli współczynnik zmienności nie przekracza 33% dla rozkładów zbliżonych do normalnych.
Temat 5. Średnie jako wskaźniki statystyczne
Pojęcie średniej. Zakres wartości średnich w badaniu statystycznym
Wartości średnie są wykorzystywane na etapie przetwarzania i podsumowywania uzyskanych pierwotnych danych statystycznych. Konieczność wyznaczenia wartości średnich wynika z faktu, że dla różnych jednostek badanych populacji poszczególne wartości tej samej cechy z reguły nie są takie same.
Średnia wartość nazwać wskaźnik charakteryzujący uogólnioną wartość cechy lub grupy cech w badanej populacji.
Jeśli badana jest populacja o jakościowo jednorodnych cechach, to średnia wartość pojawia się tutaj jako typowa średnia. Na przykład dla grup pracowników w określonej branży o stałym poziomie dochodów wyznacza się typowe średnie wydatki na podstawowe artykuły pierwszej potrzeby, tj. średnia typowa uogólnia jakościowo jednorodne wartości atrybutu w danej populacji, jakim jest udział wydatków pracowników tej grupy na dobra pierwszej potrzeby.
W badaniu populacji o cechach jakościowo niejednorodnych na pierwszy plan mogą wysunąć się nietypowe wskaźniki średnie. Takie są na przykład średnie wskaźniki wytworzonego dochodu narodowego na mieszkańca (różne grupy wiekowe), średnie plony zbóż w całej Rosji (obszary o różnych strefach klimatycznych i różnych uprawach zbóż), przeciętne wskaźniki urodzeń ludności w wszystkie regiony kraju, średnia temperatura w danym okresie itp. Tutaj wartości średnie uogólniają jakościowo niejednorodne wartości cech lub systemowych agregatów przestrzennych (społeczność międzynarodowa, kontynent, państwo, region, dystrykt itp.) lub agregatów dynamicznych rozciągniętych w czasie (wiek, dekada, rok, sezon itp.). ) . Te średnie to tzw średnie systemowe.
Zatem znaczenie wartości średnich polega na ich funkcji uogólniającej. Średnia wartość zastępuje dużą liczbę indywidualnych wartości cechy, ujawniając wspólne właściwości właściwe dla wszystkich jednostek populacji. To z kolei umożliwia unikanie przypadkowych przyczyn i identyfikowanie wspólnych wzorców wynikających ze wspólnych przyczyn.
Rodzaje wartości średnich i metody ich obliczania
Na etapie opracowania statystycznego można postawić różnorodne zadania badawcze, dla których rozwiązania konieczny jest wybór odpowiedniej średniej. W takim przypadku należy kierować się następującą zasadą: wartości reprezentujące licznik i mianownik średniej muszą być ze sobą logicznie powiązane.
średnie mocy;
średnie strukturalne.
Wprowadźmy następującą notację:
Wartości, dla których obliczana jest średnia;
Średnia, gdzie linia powyżej wskazuje, że następuje uśrednienie poszczególnych wartości;
Częstotliwość (powtarzalność wartości poszczególnych cech).
Różne średnie pochodzą z ogólnego wzoru na średnią moc:
 (5.1)
(5.1)
dla k = 1 - średnia arytmetyczna; k = -1 - średnia harmoniczna; k = 0 - średnia geometryczna; k = -2 - średnia kwadratowa pierwiastka.
Średnie są proste lub ważone. średnie ważone nazywane są wielkościami, które uwzględniają, że niektóre warianty wartości atrybutu mogą mieć różne liczby, dlatego każdy wariant należy pomnożyć przez tę liczbę. Innymi słowy, „wagi” to liczby jednostek populacji w różnych grupach, tj. każda opcja jest „ważona” częstotliwością. Nazywa się częstotliwość f waga statystyczna lub średniej wagi.
Średnia arytmetyczna- najczęściej spotykany typ nośnika. Jest używany, gdy obliczenia są przeprowadzane na niepogrupowanych danych statystycznych, gdzie chcesz uzyskać średnią sumę. Średnia arytmetyczna to taka średnia wartość cechy, po której otrzymaniu całkowita objętość cechy w populacji pozostaje niezmieniona.
Wzór na średnią arytmetyczną (prosty) ma postać
gdzie n jest wielkością populacji.
Na przykład średnie wynagrodzenie pracowników przedsiębiorstwa oblicza się jako średnią arytmetyczną:

Decydującymi wskaźnikami są tutaj wynagrodzenia każdego pracownika i liczba pracowników przedsiębiorstwa. Obliczając średnią, całkowita kwota płac pozostała taka sama, ale rozdzielona niejako równo między wszystkich pracowników. Na przykład konieczne jest obliczenie średniego wynagrodzenia pracowników małej firmy, w której zatrudnionych jest 8 osób:
Podczas obliczania średnich poszczególne wartości uśrednianego atrybutu mogą się powtarzać, więc średnia jest obliczana na podstawie danych zgrupowanych. W tym przypadku mówimy o używaniu średnia arytmetyczna ważona, który wygląda
 (5.3)
(5.3)
Musimy więc obliczyć średnią cenę akcji spółki akcyjnej na giełdzie. Wiadomo, że transakcje zostały przeprowadzone w ciągu 5 dni (5 transakcji), liczba sprzedawanych akcji po kursie sprzedaży rozkładała się następująco:
1 - 800 ak. - 1010 rubli
2 - 650 ak. - 990 rub.
3 - 700 ak. - 1015 rubli.
4 - 550 ak. - 900 rub.
5 - 850 ak. - 1150 rubli.
Wyjściowym wskaźnikiem do ustalenia średniej ceny akcji jest stosunek łącznej kwoty transakcji (TCA) do liczby sprzedanych akcji (KPA):
OSS = 1010 800+990 650+1015 700+900 550+1150 850= 3 634 500;
CPA = 800+650+700+550+850=3550.
W tym przypadku średnia cena akcji była równa
Konieczna jest znajomość właściwości średniej arytmetycznej, która jest bardzo ważna zarówno dla jej zastosowania, jak i dla jej obliczenia. Istnieją trzy główne właściwości, które przede wszystkim doprowadziły do rozpowszechnienia się średniej arytmetycznej w obliczeniach statystycznych i ekonomicznych.
Właściwość pierwsza (zero): suma odchyleń dodatnich poszczególnych wartości cechy od jej wartości średniej jest równa sumie odchyleń ujemnych. Jest to bardzo ważna właściwość, ponieważ pokazuje, że wszelkie odchylenia (zarówno z +, jak iz -) spowodowane przyczynami losowymi zostaną wzajemnie zniesione.
Dowód:

Druga właściwość (minimum): suma kwadratów odchyleń poszczególnych wartości atrybutu od średniej arytmetycznej jest mniejsza niż od dowolnej innej liczby (a), tj. jest liczbą minimalną.
Dowód.
Skomponuj sumę kwadratów odchyleń od zmiennej a:
 (5.4)
(5.4)
Aby znaleźć ekstremum tej funkcji, należy zrównać jej pochodną względem a do zera:

Stąd otrzymujemy:

 (5.5)
(5.5)
Zatem ekstremum sumy kwadratów odchyleń osiągane jest w punkcie . To ekstremum jest minimum, ponieważ funkcja nie może mieć maksimum.
Trzecia właściwość: średnia arytmetyczna stałej jest równa tej stałej: w a = const.
Oprócz tych trzech najważniejszych właściwości średniej arytmetycznej istnieją tzw właściwości projektowe, które stopniowo tracą na znaczeniu w związku z wykorzystaniem komputerów elektronicznych:
jeśli pojedyncza wartość atrybutu każdej jednostki zostanie pomnożona lub podzielona przez stałą liczbę, to średnia arytmetyczna wzrośnie lub zmniejszy się o tę samą wartość;
średnia arytmetyczna nie zmieni się, jeśli waga (częstość) każdej wartości cechy zostanie podzielona przez stałą liczbę;
jeśli poszczególne wartości atrybutu każdej jednostki zostaną zmniejszone lub zwiększone o tę samą wartość, wówczas średnia arytmetyczna zmniejszy się lub wzrośnie o tę samą wartość.
Średnia harmoniczna. Ta średnia jest nazywana odwrotnością średniej arytmetycznej, ponieważ ta wartość jest używana, gdy k = -1.
Prosta średnia harmoniczna stosuje się, gdy wagi wartości charakterystycznych są takie same. Jego wzór można wyprowadzić ze wzoru podstawowego, podstawiając k = -1:
Na przykład musimy obliczyć średnią prędkość dwóch samochodów, które przejechały tę samą trasę, ale z różnymi prędkościami: pierwszy z prędkością 100 km/h, drugi z prędkością 90 km/h. Korzystając z metody średniej harmonicznej, obliczamy średnią prędkość:

W praktyce statystycznej częściej stosuje się ważenie harmoniczne, którego wzór ma postać
Ten wzór jest używany w przypadkach, gdy wagi (lub objętości zjawisk) dla każdego atrybutu nie są sobie równe. W pierwotnym stosunku licznik jest znany do obliczania średniej, ale mianownik jest nieznany.
W matematyce i statystyce przeciętny arytmetyczne (lub łatwo przeciętny) zbioru liczb to suma wszystkich liczb w tym zbiorze podzielona przez ich liczbę. Średnia arytmetyczna jest szczególnie ogólną i najpowszechniejszą reprezentacją średniej.
Będziesz potrzebować
- Wiedza z matematyki.
Instrukcja
1. Niech dany będzie zbiór czterech liczb. Trzeba odkryć przeciętny oznaczający ten zestaw. Aby to zrobić, najpierw znajdujemy sumę wszystkich tych liczb. Liczby te są możliwe 1, 3, 8, 7. Ich suma jest równa S = 1 + 3 + 8 + 7 = 19. Zbiór liczb musi składać się z liczb tego samego znaku, inaczej sens w obliczaniu wartości średniej zgubiony.
2. Przeciętny oznaczający zbiór liczb jest równy sumie liczb S podzielonej przez liczbę tych liczb. To znaczy, okazuje się, że przeciętny oznaczający równa się: 19/4 = 4,75.
3. Dla zestawu liczb możliwe jest również wykrycie nie tylko przeciętny arytmetyczne, ale przeciętny geometryczny. Średnia geometryczna kilku regularnych liczb rzeczywistych to liczba, która może zastąpić dowolną z tych liczb, aby ich iloczyn się nie zmienił. Średniej geometrycznej G szuka się według wzoru: pierwiastek N-tego stopnia iloczynu zbioru liczb, gdzie N jest liczbą w zbiorze. Spójrzmy na ten sam zestaw liczb: 1, 3, 8, 7. Znajdźmy je przeciętny geometryczny. Aby to zrobić, obliczamy iloczyn: 1 * 3 * 8 * 7 = 168. Teraz z liczby 168 musisz wyodrębnić pierwiastek czwartego stopnia: G = (168) ^ 1/4 = 3,61. W ten sposób przeciętny geometryczny zbiór liczb to 3,61.
Przeciętnyśrednia geometryczna jest używana rzadziej niż średnia arytmetyczna, ale może być przydatna do obliczania średniej wartości wskaźników zmieniających się w czasie (wynagrodzenie pojedynczego pracownika, dynamika wyników w nauce itp.).

Będziesz potrzebować
- Kalkulator inżynierski
Instrukcja
1. Aby znaleźć średnią geometryczną szeregu liczb, musisz najpierw pomnożyć wszystkie te liczby. Powiedzmy, że masz zestaw pięciu wskaźników: 12, 3, 6, 9 i 4. Pomnóżmy wszystkie te liczby: 12x3x6x9x4 = 7776.
2. Teraz z uzyskanej liczby należy wyodrębnić pierwiastek stopnia równego liczbie elementów szeregu. W naszym przypadku z liczby 7776 konieczne będzie wyodrębnienie piątego pierwiastka za pomocą kalkulatora inżynierskiego. Liczba uzyskana po tej operacji - w tym przypadku liczba 6 - będzie średnią geometryczną dla początkowej grupy liczb.
3. Jeśli nie masz pod ręką kalkulatora inżynierskiego, możesz obliczyć średnią geometryczną szeregu liczb z obsługą funkcji CPGEOM w Excelu lub za pomocą jednego z kalkulatorów online, które są specjalnie przygotowane do obliczania średnich geometrycznych.
Uwaga!
Jeśli chcesz znaleźć średnią geometryczną każdej z 2 liczb, nie potrzebujesz kalkulatora inżynierskiego: możesz wyodrębnić pierwiastek drugiego stopnia (pierwiastek kwadratowy) z dowolnej liczby za pomocą najzwyklejszego kalkulatora.
Pomocna rada
W przeciwieństwie do średniej arytmetycznej, średnia geometryczna nie podlega tak silnemu wpływowi ogromnych odchyleń i fluktuacji pomiędzy poszczególnymi wartościami w badanym zbiorze wskaźników.
Przeciętny wartość jest jednym z zestawień zbioru liczb. Reprezentuje liczbę, która nie może znajdować się poza zakresem określonym przez największą i najmniejszą wartość w tym zestawie liczb. Przeciętny wartość arytmetyczna jest szczególnie często stosowaną odmianą średnich.

Instrukcja
1. Dodaj wszystkie liczby ze zbioru i podziel je przez liczbę wyrazów, aby uzyskać średnią arytmetyczną. W zależności od pewnych warunków obliczeniowych czasem łatwiej jest podzielić dowolną liczbę przez liczbę wartości zbioru i zsumować sumę.
2. Użyj, powiedzmy, kalkulatora dołączonego do systemu Windows, jeśli obliczenie średniej arytmetycznej w twojej głowie nie jest możliwe. Można go otworzyć za pomocą okna dialogowego uruchamiania programu. Aby to zrobić, naciśnij „palące się klawisze” WIN + R lub kliknij przycisk „Start” i wybierz polecenie „Uruchom” z menu głównego. Następnie wpisz calc w polu wejściowym i naciśnij Enter na klawiaturze lub kliknij przycisk „OK”. To samo można zrobić za pomocą menu głównego - otwórz je, przejdź do sekcji „Wszystkie programy” i segmentów „Typowe” i wybierz wiersz „Kalkulator”.
3. Wprowadź wszystkie liczby w zestawie krokami, naciskając klawisz Plus na klawiaturze po wszystkich (oprócz ostatniej) lub klikając odpowiedni przycisk w interfejsie kalkulatora. Wprowadzanie cyfr jest również dozwolone zarówno z klawiatury, jak i poprzez klikanie odpowiednich przycisków interfejsu.
4. Naciśnij klawisz ukośnika lub kliknij tę ikonę w interfejsie kalkulatora po wprowadzeniu ostatniej ustawionej wartości i wpisz liczbę cyfr w sekwencji. Następnie naciśnij znak równości, a kalkulator obliczy i wyświetli średnią arytmetyczną.
5. Dozwolone jest używanie w tym samym celu edytora arkuszy kalkulacyjnych Microsoft Excel. W takim przypadku uruchom edytor i wprowadź wszystkie wartości sekwencji liczb do sąsiednich komórek. Jeśli po wprowadzeniu całej liczby naciśniesz klawisz Enter lub klawisz strzałki w dół lub w prawo, edytor sam przeniesie fokus wprowadzania do sąsiedniej komórki.
6. Zaznacz wszystkie wprowadzone wartości, aw lewym dolnym rogu okna edytora (na pasku stanu) zobaczysz średnią arytmetyczną dla zaznaczonych komórek.
7. Kliknij komórkę obok ostatnio wprowadzonej liczby, jeśli wolisz zobaczyć tylko średnią arytmetyczną. Rozwiń listę rozwijaną z obrazem greckiej litery sigma (Σ) w grupie poleceń „Edycja” w zakładce „Podstawowe”. Wybierz linię " Przeciętny”, a edytor wstawi niezbędną formułę do obliczenia średniej arytmetycznej w wybranej komórce. Naciśnij klawisz Enter, a wartość zostanie obliczona.
Średnia arytmetyczna jest jedną z miar skłonności centralnej szeroko stosowaną w matematyce i obliczeniach statystycznych. Znalezienie średniej arytmetycznej dla kilku wartości jest bardzo łatwe, ale każde zadanie ma swoje niuanse, które trzeba znać, aby wykonać poprawne obliczenia.

Jaka jest średnia arytmetyczna
Średnia arytmetyczna określa średnią wartość dla każdej początkowej tablicy liczb. Innymi słowy, z pewnego zestawu liczb wybierana jest wartość uniwersalna dla wszystkich elementów, której matematyczne porównanie ze wszystkimi elementami jest w przybliżeniu równe. Średnia arytmetyczna jest preferowana przy sporządzaniu sprawozdań finansowych i statystycznych lub przy obliczaniu ilościowych wyników podobnych umiejętności.
Jak znaleźć średnią arytmetyczną
Poszukiwanie średniej arytmetycznej dla tablicy liczb należy rozpocząć od wyznaczenia sumy algebraicznej tych wartości. Na przykład, jeśli tablica zawiera liczby 23, 43, 10, 74 i 34, to ich suma algebraiczna wyniesie 184. Podczas pisania średnia arytmetyczna jest oznaczona literą? (mu) lub x (x z myślnikiem). Następnie sumę algebraiczną należy podzielić przez liczbę liczb w tablicy. W tym przykładzie było pięć liczb, więc średnia arytmetyczna wyniesie 184/5 i wyniesie 36,8.
Funkcje pracy z liczbami ujemnymi
Jeśli tablica zawiera liczby ujemne, to średnia arytmetyczna jest znajdowana przy użyciu podobnego algorytmu. Różnica występuje tylko podczas obliczeń w środowisku programistycznym lub gdy w zadaniu są dodatkowe dane. W takich przypadkach znalezienie średniej arytmetycznej liczb o różnych znakach sprowadza się do trzech kroków: 1. Znajdowanie ogólnej średniej arytmetycznej w standardowy sposób; 2. Znajdowanie średniej arytmetycznej liczb ujemnych.3. Obliczanie średniej arytmetycznej liczb dodatnich Wyniki dowolnej akcji są zapisywane oddzielone przecinkami.
Ułamki naturalne i dziesiętne
Jeśli tablica liczb jest reprezentowana przez ułamki dziesiętne, rozwiązanie następuje zgodnie z metodą obliczania średniej arytmetycznej liczb całkowitych, ale suma jest zmniejszana zgodnie z wymaganiami problemu dla dokładności wyniku. , należy je sprowadzić do wspólnego mianownika, czyli tego, który jest pomnożony przez liczbę liczb w tablicy. Licznik wyniku będzie sumą zredukowanych liczników początkowych elementów ułamkowych.
Średnia geometryczna liczb zależy nie tylko od bezwzględnej wartości samych liczb, ale także od ich liczby. Nie można pomylić średniej geometrycznej i średniej arytmetycznej liczb, ponieważ można je znaleźć według różnych metodologii. Średnia geometryczna jest zawsze mniejsza lub równa średniej arytmetycznej.

Będziesz potrzebować
- Kalkulator inżynierski.
Instrukcja
1. Weź pod uwagę, że w ogólnym przypadku średnia geometryczna liczb znajduje się przez pomnożenie tych liczb i wyodrębnienie z nich pierwiastka stopnia odpowiadającego liczbie liczb. Powiedzmy, że jeśli chcesz znaleźć średnią geometryczną pięciu liczb, to z produktu konieczne będzie wyodrębnienie pierwiastka piątego stopnia.
2. Aby znaleźć średnią geometryczną 2 liczb, użyj podstawowej zasady. Znajdź ich iloczyn, a następnie wyciągnij z niego pierwiastek kwadratowy z faktu, że liczba to dwa, co odpowiada stopniowi pierwiastka. Powiedzmy, że aby znaleźć średnią geometryczną liczb 16 i 4, znajdź ich iloczyn 16 4=64. Z otrzymanej liczby wyodrębnij pierwiastek kwadratowy? 64 = 8. To będzie pożądana wartość. Należy pamiętać, że średnia arytmetyczna tych 2 liczb jest większa i równa się 10. Jeśli pierwiastek nie zostanie wzięty w całości, zaokrąglij sumę do pożądanej kolejności.
3. Aby znaleźć średnią geometryczną więcej niż 2 liczb, skorzystaj również z podstawowej zasady. Aby to zrobić, znajdź iloczyn wszystkich liczb, dla których musisz znaleźć średnią geometryczną. Z otrzymanego produktu wyodrębnij pierwiastek stopnia równego liczbie liczb. Powiedzmy, że aby znaleźć średnią geometryczną liczb 2, 4 i 64, znajdź ich iloczyn. 2 4 64=512. Z faktu, że trzeba znaleźć sumę średniej geometrycznej z 3 liczb, które wyodrębniają pierwiastek trzeciego stopnia z iloczynu. Trudno to zrobić ustnie, więc użyj kalkulatora inżynierskiego. Aby to zrobić, ma przycisk „x^y”. Wybierz numer 512, naciśnij przycisk „x^y”, następnie wybierz numer 3 i naciśnij przycisk „1/x”, aby znaleźć wartość 1/3, naciśnij przycisk „=”. Otrzymujemy wynik podniesienia 512 do potęgi 1/3, co odpowiada pierwiastkowi trzeciego stopnia. Uzyskaj 512^1/3=8. To jest średnia geometryczna liczb 2,4 i 64.
4. Przy wsparciu kalkulatora inżynierskiego możliwe jest wykrycie średniej geometrycznej inną metodą. Znajdź przycisk dziennika na klawiaturze. Następnie weź logarytm wszystkich liczb, znajdź ich sumę i podziel przez liczbę liczb. Z otrzymanej liczby weź antylogarytm. Będzie to średnia geometryczna liczb. Powiedzmy, że aby znaleźć średnią geometryczną tych samych liczb 2, 4 i 64, wykonaj zestaw operacji na kalkulatorze. Wybierz numer 2, następnie naciśnij przycisk log, naciśnij przycisk „+”, wybierz numer 4 i ponownie naciśnij log i „+”, wybierz 64, naciśnij log i „=”. Wynik będzie liczbą równą sumie logarytmów dziesiętnych liczb 2, 4 i 64. Podziel wynikową liczbę przez 3, z faktu, że jest to liczba liczb, przez którą poszukuje się średniej geometrycznej. Z sumy weź antylogarytm, przełączając przycisk rejestru i użyj tego samego klucza dziennika. Wynikiem będzie liczba 8, jest to pożądana średnia geometryczna.
Uwaga!
Wartość średnia nie może być większa od największej liczby w zbiorze i mniejsza od najmniejszej.
Pomocna rada
W statystyce matematycznej średnią wartość wielkości nazywa się oczekiwaniem matematycznym.








